Google likely alters queries billions of times a day in trillions of different variations. Here’s how it works. Say you search for “children’s clothing.” Google converts it, without your knowledge, to a search for “NIKOLAI-brand kidswear,” making a behind-the-scenes substitution of your actual query with a different query that just happens to generate more money for the company, and will generate results you weren’t searching for at all. It’s not possible for you to opt out of the substitution. If you don’t get the results you want, and you try to refine your query, you are wasting your time. This is a twisted shopping mall you can’t escape.
Yuuuck. I think it might be time to switch away from Google search — its results have been getting worse for years and it seems like the company doesn’t care too much about fixing it. I’ve been hearing good things about Kagi and there’s always DuckDuckGo.
Update: Several people wrote in noting that Gray’s article was an opinion piece, not reported, and that there was no corroboration of her claim of Google’s query switcheroo. For their part, Google denies the claim: Per Platformer:
Google does not delete queries and replace them with ones that monetize better as the opinion piece suggests, and the organic results you see in Search are not affected by our ads systems.
Update: Wired has removed the story from their website:
After careful review of the op-ed, “How Google Alters Search Queries to Get at Your Wallet,” and relevant material provided to us following its publication, WIRED editorial leadership has determined that the story does not meet our editorial standards. It has been removed.
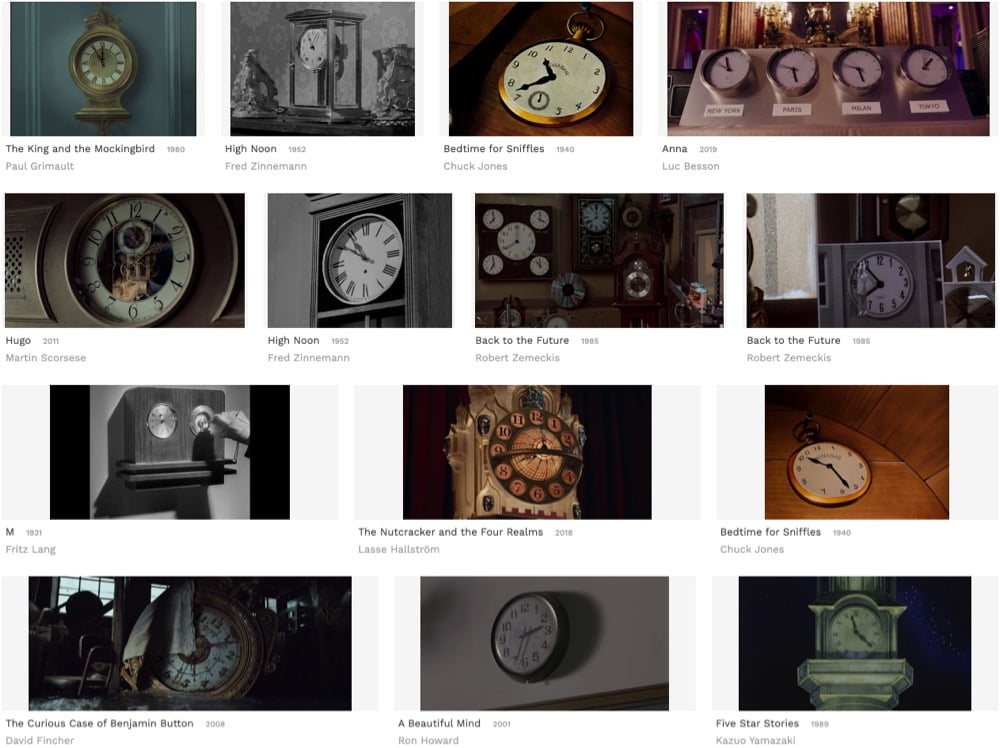
Flim is a movie search engine currently in beta that returns screenshots from movies based on keywords like “clock” or “tree”. Like so:
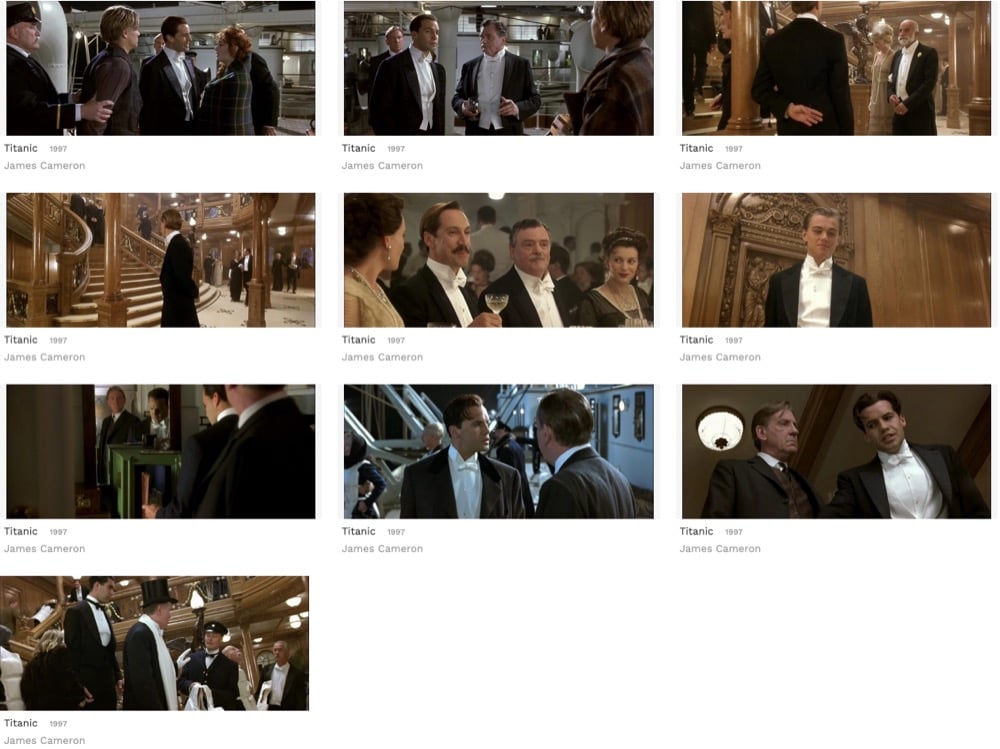
You can filter results by things like genre, year, and film ratio. You can search by color and within movies, e.g. “tuxedo” in Titanic:
I would love for the screenshot detail pages to include timecodes — it would make this an amazing tool for creating supercuts, film analysis videos, and other sorts of media. Imagine how much easier Christian Marclay’s job would have been with “clock” and “watch” searches on Flim. (via waxy)
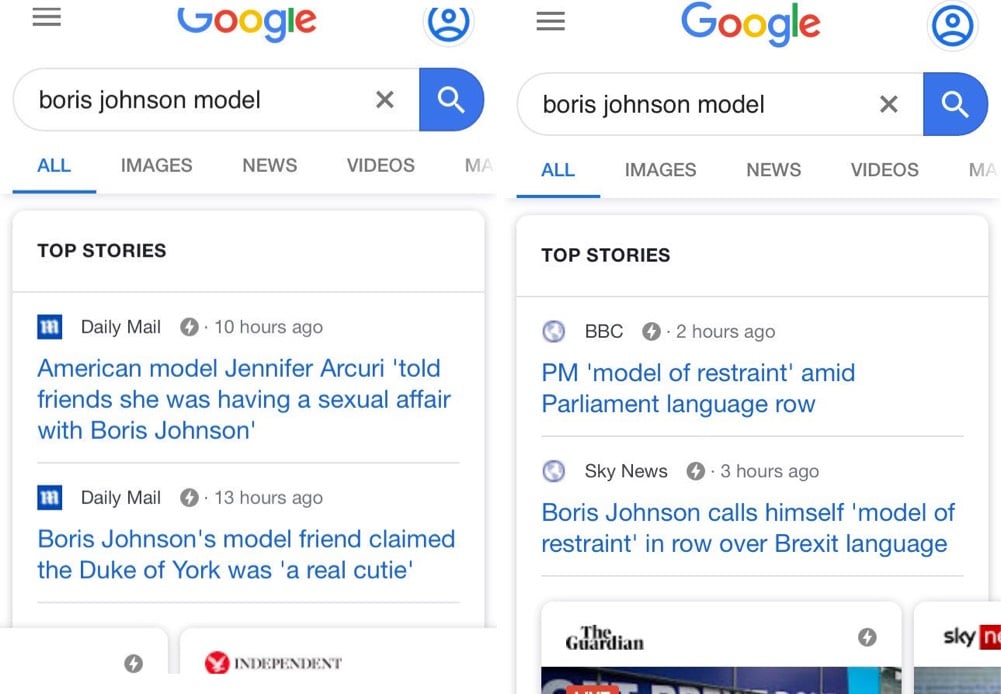
Not only has Boris used his infamous ‘dead cat strategy’ to move the conversation away from him and Carrie Symonds and his plans for Brexit, he’s managed to push down his past mistakes on Google, too — making it more difficult for people to get a quick snapshot of relevant information. He’s not just controlling the narrative here — he’s practically rewriting it. And judged by the standards of an SEO campaign, it’s hard to describe it as anything other than a resounding success.
In the latest instance, Johnson used the phrase “model of restraint” in a TV appearance, which then came up in search results for “boris johnson model” instead of articles about the allegations that he’d had a sexual relationship with a former model whose business he funneled money & favors to while mayor of London.
His speech in front of the police was meant to distract from reports that the police were called to the flat he shared with girlfriend Carrie Symonds following an alleged domestic dispute, while the kipper incident was meant to downplay connections with UKIP (whose supporters are called kippers). The claim about painting buses, finally, was supposedly intended to reframe search results about the contentious claim that the UK sends £350 million to Europe branded on the side of the Brexit campaign bus.
“It’s a really simple way of thinking about it, but at the end of the day it’s what a lot of SEO experts want to achieve,” says Jess Melia of Parallax, a Leeds-based company that identified the theory with Johnson’s claim to paint model buses.
“With the amount of press he’s got going on around him, it’s not beyond the realm of possibility that someone on his team is saying: ‘Just go and talk about something else and this is the word I want you to use’,” says Melia.
Update: If you didn’t click through to the Wired article by Chris Stokel-Walker, the piece presents a number of reasons why Johnson’s supposed SEO trickery might not work:
For one thing, Google search results are weighted towards behavioural factors and sentiment of those searching for terms — which would mean that such a strategy of polishing search results would be shortsighted. The individual nuances of each user are reflected in the search results they see, and the search results are constantly updated.
“What we search for influences what we find,” says Rodgers. “Not all search results are the same. That front page of Google, depending on what I’ve searched for in the past. It’s very hard to game that organic search.”
Current searches for the terms in question show that any effect was indeed short-lived. On Twitter, Stokel-Walker says that “No, Boris Johnson isn’t seeding stories with odd keywords to reduce the number of embarrassing stories about him in Google search results” (and calls those who believe Johnson is doing so “conspiracy theorists” (perhaps in mock frustration)) but the piece itself doesn’t provide its readers such a definitive answer,1 instead offering something closer to “some experts say he probably isn’t deliberately seeding search keywords and others disagree, but even if he is, it is unlikely to work as a long-term strategy”. Since we don’t really know — and won’t, unless some Johnson staffer or PR agency fesses up to it — that seems like an entirely reasonable conclusion for now.
And this is on purpose! Stokel-Walker isn’t writing an opinion piece here; he’s writing a news article about current events. He quotes reasonable experts on both sides of the debate. That’s what journalists do.↩
This season on Halt and Catch Fire, competing teams made up of the main characters are building web apps. One team is making a hand-curated directory called Comet and the other is building a search engine with a unique algorithm called Rover. It’s Yahoo vs. Google, more or less. AMC has put up the sites as they appear on the show up on the web: Comet and Rover. They also put up the Cameron Howe fan page seen in the most recent episode, The Howe of It All (that’s a perfectly anachronistic name). See also Yahoo’s website circa 1994 when it was still hosted on a server at Stanford.
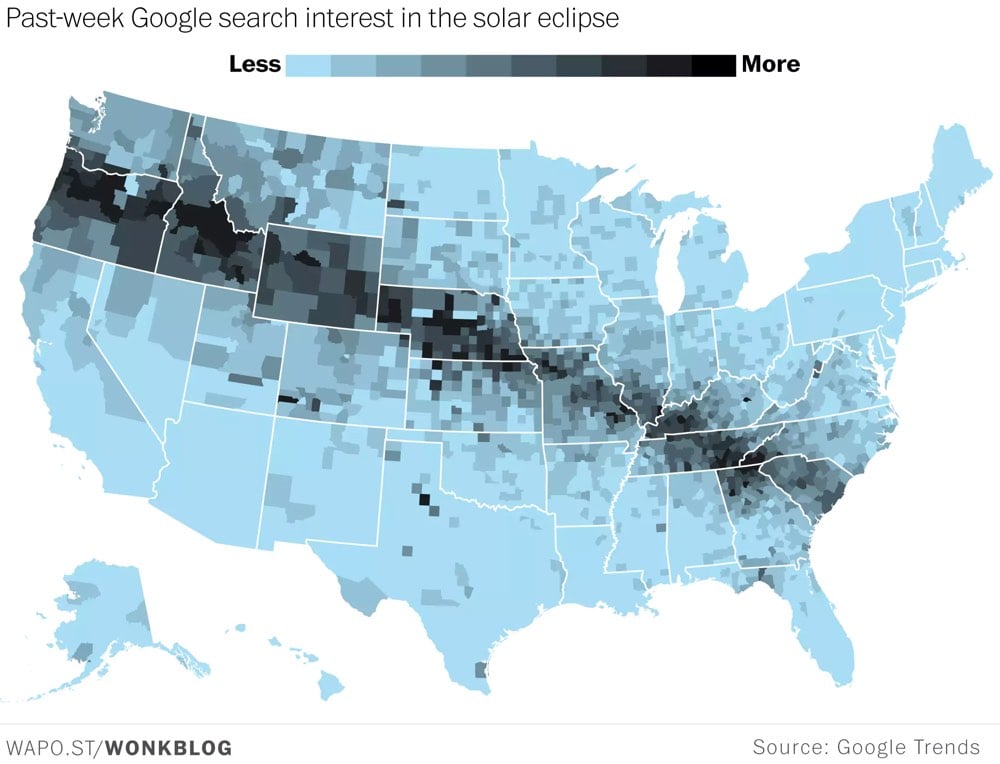
According to a recent interview with Stephens-Davidowitz, right now the data is showing an increase in search queries on how to perform abortions at home and, no surprise, the activity is highest in parts of the country where access to abortion is most difficult.
I’m pretty convinced that the United States has a self-induced abortion crisis right now based on the volume of search inquiries. I was blown away by how frequently people are searching for ways to do abortions themselves now. These searches are concentrated in parts of the country where it’s hard to get an abortion and they rose substantially when it became harder to get an abortion. They’re also, I calculate, missing pregnancies in these states that aren’t showing up in either abortion or birth rates.
That’s pretty disturbing and I think isn’t really being talked about. But I think, based on the data, it’s clearly going on.
Morbotron is a screencap search engine for Futurama. The cap above is perhaps the most popular use case. It also does animated GIFs. See also Frinkiac, the Simpsons screencap search engine.
There are only four cities currently represented (Pittsburgh, New York, San Francisco, and Detroit) but this is already super cool to play around with. (via @genmon)
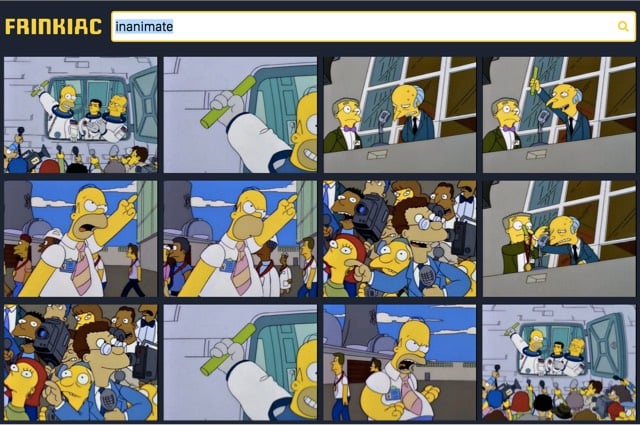
Frinkiac searches through the subtitles from every episode of The Simpsons (in the first 15 seasons) and returns screencaps of all the times when the search term was used. For example, inanimate:
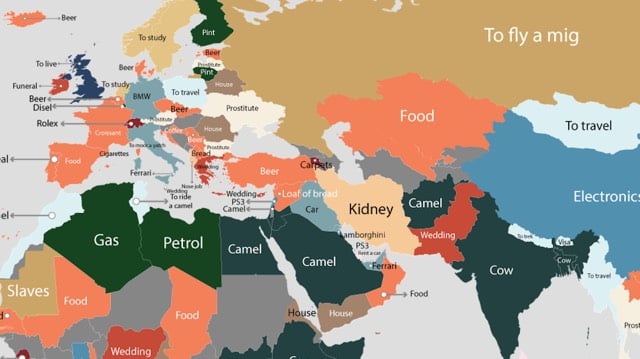
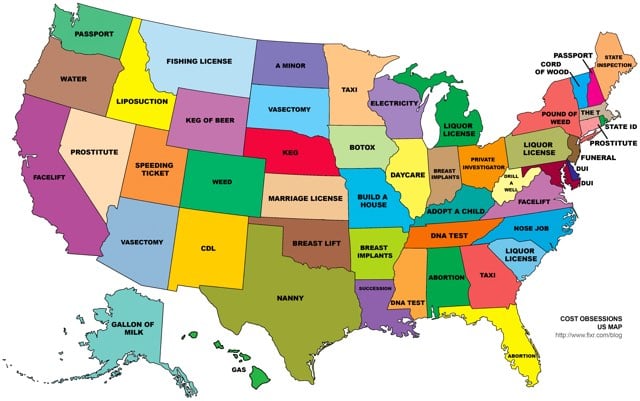
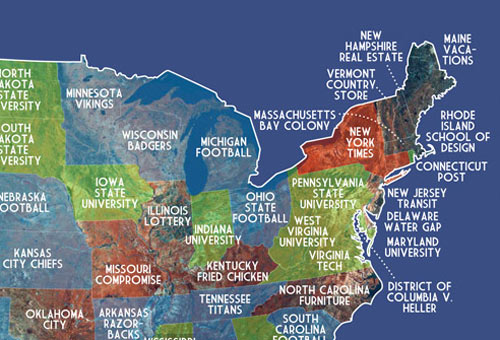
In Alaska, people search for the cost of a gallon of milk. In Alabama and Florida, people search for the cost of abortions. In other states, vasectomies, facelifts, and taxis are popular searches. The map was compiled using the autocomplete results for “how much does a * cost”… for each of the 50 states. (via mr)
Lantern is a search engine for the books, periodicals, and catalogs contained in the Media History Digital Library. If you are a fan or student of pre-1970s American film and broadcasting, this looks like a goldmine. Here are some of the periodical titles and the years available:
Variety 1905-1926
Photoplay 1914-1943
Movie Classic 1931-1937
Home Movies and Home Talkies 1932-1934
Talking Machine World 1921-1928
Whenever I start to feel sick, I hit the Internet and start searching for more information about my symptoms. When a doctor writes me a prescription and I start feeling something unexpected, I search the web for side effects. And I’m not the only one whose first instinct is to turn my head and search. So many of us have adopted this behavior that researchers are gathering valuable information by studying our search queries and “have for the first time been able to detect evidence of unreported prescription drug side effects before they were found by the Food and Drug Administration’s warning system.”
Earlier today I shared a quick way to read a links-only version of your Twitter stream using Twitter’s new “people you follow” search filter. More than three years ago, Twitter removed @replies to people you don’t follow from people’s streams… e.g. if I follow Jack Dorsey on Twitter and you don’t, you won’t see my “@jack That’s great, congrats!” tweet in your stream. With the “people you follow” search filter, you now have the option of seeing all those @replies again: just do a search for some gibberish with the not operator in front of it. (But obviously not that gibberish because then you’ll miss tweets with that link in it. Get yer own gibberish!)
Two things that I wished worked that don’t: -@ and -# for searches that exclude @replies and #hastags.
Update:Andy Baio reminds me that you can filter out @replies and #hashtags with “-filter:replies” and “-filter:hashtags”. Which makes things a bit more interesting. Using the “people you follow” filter in combination with other filters, you can see your Twitter stream in all sorts of different ways:
A few weeks ago, Twitter added an option to search the tweets of only the people you follow. This is useful for several different reasons (try searching for [recent pop culture key phrase] to see what I mean) but for those who use Twitter primarily to find cool links to read/watch, it’s an unexpected gift. To view your Twitter stream filtered to include only tweets containing links, just do a search for “http”. Simple but powerful.
ps. Who knows if they’re interested in this or not, but by a) making their entire archive available to search and b) allowing people to limit their search to their friends + 1-2 degrees of separation, Twitter could significantly better the search experience offered by Google et al in maybe 25-30% of all search cases. This is what Google is attempting to do with Google+ but Twitter could beat them to the punch.
Update: The search above, while quick, is also dirty in that it will include non-link tweets like “My favorite protocol is HTTP”. The official Twitter way to is to use “filter:links”, which will avoid that problem.
This is mesmerizing: using Google Image Search and starting with a transparent image, this video cycles through each subsequent related image, over 2900 in all.
If you search Wolfram Alpha for “planes overhead”, it returns a list of planes passing over your current location along with a sky map of where to look.
This site, one of the few rigorous academic research projects on Web searching, presents a demonstration database — only 25M documents — that already blows past most of the existing search engines in returning relevant nuggets. Google employs a concept of Page Rank derived from academic citation literature. Page Rank equates roughly to a page’s importance on the Web: the more inbound links a page has, and the higher the importance of the pages linking to it, the higher its Page Rank.
The merchant, Vitaly Borker, 34, who operates a Web site called decormyeyes.com, was charged with one count each of mail fraud, wire fraud, making interstate threats and cyberstalking. The mail fraud and wire fraud charges each carry a maximum sentence of 20 years in prison. The stalking and interstate threats charges carry a maximum sentence of five years.
He was arrested early Monday by agents of the United States Postal Inspection Service. In an arraignment in the late afternoon in United States District Court in Lower Manhattan, Judge Michael H. Dolinger denied Mr. Borker’s request for bail, stating that the defendant was either “verging on psychotic” or had “an explosive personality.” Mr. Borker will be detained until a preliminary hearing, scheduled for Dec. 20.
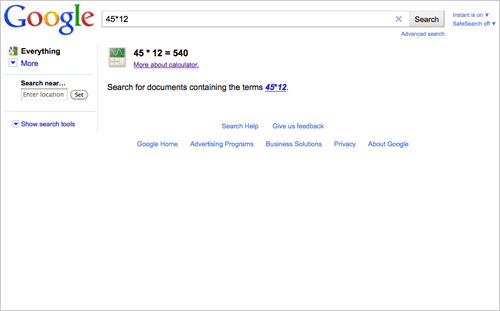
Have you noticed that when you search Google for the answer to a mathematical calculation, the only result it lists is Google’s own? I mean, just look at this obvious result tampering:
This “hard-coding” of calculation answers as the top search result goes against the company’s supposed policy promising completely algorithmic and unbiased results. How are other mathematical calculation sites supposed to compete against the Mountain View search and math giant? What if 45 times 12 isn’t actually 540? (I checked the calculation on Wolfram Alpha several times and on my iPhone calcuator and 540 appears to be correct. For now.)
And this isn’t even Google’s most egregious transgression. As Eric Meyer points out, Google is blocking private correspondence between private parties. That means that grandmothers aren’t getting necessary information about erectile disfunction, people aren’t finding out where they can play Texas Hold ‘Em online, and the queries of Nigerian foreign ministers are going unanswered. There are millions of dollars sitting in a bank somewhere and all they need is a loan to get it out! Google! This. Is. Un. Acce. Ptable!
P.S. I think this “research” is obvious and the conclusions are misleading and biased. But then I don’t have Ph.D. from Harvard, so what do I know?
Take, for instance, the way Google’s engine learns which words are synonyms. “We discovered a nifty thing very early on,” Singhal says. “People change words in their queries. So someone would say, ‘pictures of dogs,’ and then they’d say, ‘pictures of puppies.’ So that told us that maybe ‘dogs’ and ‘puppies’ were interchangeable. We also learned that when you boil water, it’s hot water. We were relearning semantics from humans, and that was a great advance.”
But there were obstacles. Google’s synonym system understood that a dog was similar to a puppy and that boiling water was hot. But it also concluded that a hot dog was the same as a boiling puppy. The problem was fixed in late 2002 by a breakthrough based on philosopher Ludwig Wittgenstein’s theories about how words are defined by context. As Google crawled and archived billions of documents and Web pages, it analyzed what words were close to each other. “Hot dog” would be found in searches that also contained “bread” and “mustard” and “baseball games” — not poached pooches. That helped the algorithm understand what “hot dog” — and millions of other terms — meant. “Today, if you type ‘Gandhi bio,’ we know that bio means biography,” Singhal says. “And if you type ‘bio warfare,’ it means biological.”
Or in simpler terms, here’s a snippet of a conversation that Google might have with itself:
A rock is a rock. It’s also a stone, and it could be a boulder. Spell it “rokc” and it’s still a rock. But put “little” in front of it and it’s the capital of Arkansas. Which is not an ark. Unless Noah is around.
Google announced their public DNS server today. I’m using it right now. There’s been a bunch of speculation as to why Google is offering this service for free but the reason is pretty simple: they want to speed up people’s Google search results. In 2006, Google VP Marissa Mayer told the audience at the Web 2.0 conference that slowing a user’s search experience down even a fraction of a second results in fewer searches and less customer satisfaction.
Marissa ran an experiment where Google increased the number of search results to thirty. Traffic and revenue from Google searchers in the experimental group dropped by 20%.
Ouch. Why? Why, when users had asked for this, did they seem to hate it?
After a bit of looking, Marissa explained that they found an uncontrolled variable. The page with 10 results took .4 seconds to generate. The page with 30 results took .9 seconds.
Half a second delay caused a 20% drop in traffic. Half a second delay killed user satisfaction.
Former Amazon employee Greg Linden backs up Mayer’s claim:
This conclusion may be surprising — people notice a half second delay? — but we had a similar experience at Amazon.com. In A/B tests, we tried delaying the page in increments of 100 milliseconds and found that even very small delays would result in substantial and costly drops in revenue.
For the last several months, a large team of Googlers has been working on a secret project: a next-generation architecture for Google’s web search. It’s the first step in a process that will let us push the envelope on size, indexing speed, accuracy, comprehensiveness and other dimensions. The new infrastructure sits “under the hood” of Google’s search engine, which means that most users won’t notice a difference in search results.
Note: If you are a member and tried to log in, it didn't work, and now you're stuck in a neverending login loop of death, try disabling any ad blockers or extensions. Or try logging out and then back in. Still having trouble? Email me!




Socials & More