kottke.org posts about Google
Google is thirteen today…back in 1998 when the site was still hosted at http://google.stanford.edu, Keith Dawson gave the search engine its first online coverage in English on the fondly remembered Tasty Bits From the Technology Front.
This site, one of the few rigorous academic research projects on Web searching, presents a demonstration database — only 25M documents — that already blows past most of the existing search engines in returning relevant nuggets. Google employs a concept of Page Rank derived from academic citation literature. Page Rank equates roughly to a page’s importance on the Web: the more inbound links a page has, and the higher the importance of the pages linking to it, the higher its Page Rank.
This is kind of amazing…you draw a graph and Google Correlate finds query terms whose popularity matches the drawn curve. I drew a bell curve, a very rough one peaking in 2007, and it matches a bunch of searches for “myspace”.
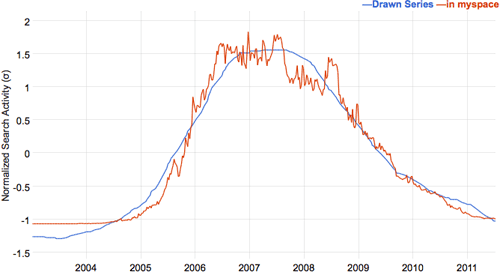
This fits beautifully with the previous post about Vonnegut’s story shape graphs.
Charlie Ayers, former executive chef for Google, once worked alongside a former cook for Elvis Presley and that cook gave him his special recipe for fried chicken. Ayers says it’s “the best southern fried chicken I [have] ever tasted”. The recipe uses Google-sized portions…here’s a recipe converter to scale it down.
Rorschmap is a trippy Google Maps mashup by James Bridle that provides kaleidoscopic views of locations from around the world. Here’s Paris, complete with MegaSeine.
I feel like I’ve heard this before, but in the early days of Google, Sergey Brin ended his job interviews in an unusual manner.
Finally, he leaned forward and fired his best shot, what he came to call “the hard question.”
“I’m going to give you five minutes,” he told me. “When I come back, I want you to explain to me something complicated that I don’t already know.” He then rolled out of the room toward the snack area. I looked at Cindy. “He’s very curious about everything,” she told me. “You can talk about a hobby, something technical, whatever you want. Just make sure it’s something you really understand well.”
I wonder if Mark Zuckerberg asks similar sorts of questions on his walks in the woods.
There’s a serious proposal to build an undersea electrical grid as part of the infrastructure for future offshore wind turbines. David Roberts writes about its importance:
Offshore wind power has significant advantages over the onshore variety. Uninterrupted by changes in terrain, the wind at sea blows steadier and stronger. Installing turbines far enough from shore that they’re invisible except on the very clearest days lessens the possibility of not-in-my-backyard resistance. The challenge is getting the electricity back to land, to the people who will use it…
The Atlantic Wind Connection (AWC) would provide multiple transmission hubs for future wind farms, making the waters off the mid-Atlantic coast an attractive and economical place for developers to set up turbines. The AWC’s lines could transmit as much as six gigawatts of low-carbon power from turbines back to the coast—the equivalent capacity of 10 average coal-fired power plants.
There’s a particular stretch of seabed, a flat shelf between the north Jersey and southern Virginia, that’s geologically and geographically perfect for this. That’s where they’re setting up shop. Power-hungry Google is helping foot the bill.
(via Grist.)
On April 29th, Google is shutting down playback at Google Video. Instead of transitioning everything over to YouTube (which would seemingly make a lot of sense), they’re just shutting it down with two weeks notice. If you’re comfortable with the command line (can’t they make this easier?), you can help archive.org save some of the best of Google Video. (via waxy)
Google has built a quick little app for people trying to locate friends and family in Japan. There are two options: 1) “I’m looking for someone” and 2) “I have information about someone”.
You’ve likely already seen this, but 9-eyes is a better-than-usual collection of images taken from Google Street View.

Over at the New Yorker, Ken Auletta has some insight into why Eric Schmidt is stepping down as Google’s CEO.
Schmidt, according to associates, lost some energy and focus after losing the China decision. At the same time, Google was becoming defensive. All of their social-network efforts had faltered. Facebook had replaced them as the hot tech company, the place vital engineers wanted to work. Complaints about Google bureaucracy intensified. Governments around the world were lobbing grenades at Google over privacy, copyright, and size issues. The “don’t be evil” brand was getting tarnished, and the founders were restive. Schmidt started to think of departing. Nudged by a board-member friend and an outside advisor that he had to re-energize himself, he decided after Labor Day that he could reboot.
He couldn’t. By the end of the year, he was ready to jump on his own.
Why can’t all “tech” journalism be like this? A single article on the topic, three paragraphs, all fact, properly sourced, no opinion, little speculation, no quotes from useless analysts. Reading something this spare and straightforward makes you realize how shitty TC, Mashable, SAI, and rest are.
Eric Schmidt is stepping down as CEO (he’ll remain the Executive Chairman) and Larry Page will become the new CEO in April.
Larry will now lead product development and technology strategy, his greatest strengths, and starting from April 4 he will take charge of our day-to-day operations as Google’s Chief Executive Officer. In this new role I know he will merge Google’s technology and business vision brilliantly. I am enormously proud of my last decade as CEO, and I am certain that the next 10 years under Larry will be even better! Larry, in my clear opinion, is ready to lead.
Sergey has decided to devote his time and energy to strategic projects, in particular working on new products. His title will be Co-Founder. He’s an innovator and entrepreneur to the core, and this role suits him perfectly.
As Executive Chairman, I will focus wherever I can add the greatest value: externally, on the deals, partnerships, customers and broader business relationships, government outreach and technology thought leadership that are increasingly important given Google’s global reach; and internally as an advisor to Larry and Sergey.
Dorothy Gambrell looked up all of the state names on Google and made a map of what the autocomplete suggestions were. Here’s part of it:
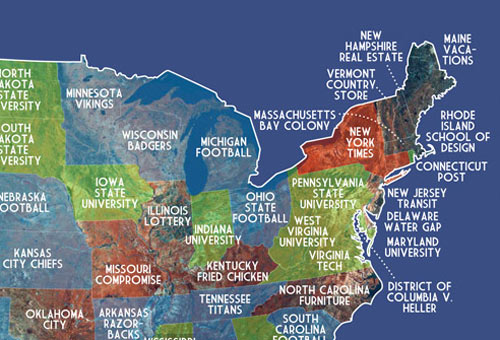
Lots of sports and schools.
The dickwad who threatened his customers as an SEO tactic (detailed here in the NY Times) was arrested on Monday by federal agents.
The merchant, Vitaly Borker, 34, who operates a Web site called decormyeyes.com, was charged with one count each of mail fraud, wire fraud, making interstate threats and cyberstalking. The mail fraud and wire fraud charges each carry a maximum sentence of 20 years in prison. The stalking and interstate threats charges carry a maximum sentence of five years.
He was arrested early Monday by agents of the United States Postal Inspection Service. In an arraignment in the late afternoon in United States District Court in Lower Manhattan, Judge Michael H. Dolinger denied Mr. Borker’s request for bail, stating that the defendant was either “verging on psychotic” or had “an explosive personality.” Mr. Borker will be detained until a preliminary hearing, scheduled for Dec. 20.
The latest big thing from Google: beatboxing. Just go to this page on Google Translate and press “Listen”. I laughed out loud. (via prosthetic knowledge)
Have you noticed that when you search Google for the answer to a mathematical calculation, the only result it lists is Google’s own? I mean, just look at this obvious result tampering:
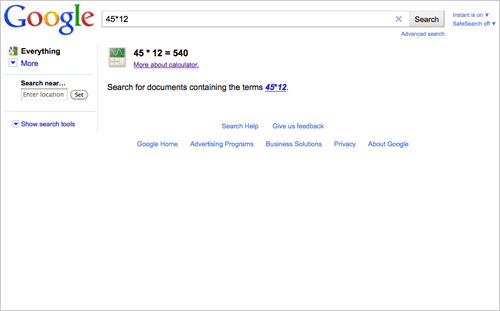
This “hard-coding” of calculation answers as the top search result goes against the company’s supposed policy promising completely algorithmic and unbiased results. How are other mathematical calculation sites supposed to compete against the Mountain View search and math giant? What if 45 times 12 isn’t actually 540? (I checked the calculation on Wolfram Alpha several times and on my iPhone calcuator and 540 appears to be correct. For now.)
And this isn’t even Google’s most egregious transgression. As Eric Meyer points out, Google is blocking private correspondence between private parties. That means that grandmothers aren’t getting necessary information about erectile disfunction, people aren’t finding out where they can play Texas Hold ‘Em online, and the queries of Nigerian foreign ministers are going unanswered. There are millions of dollars sitting in a bank somewhere and all they need is a loan to get it out! Google! This. Is. Un. Acce. Ptable!
P.S. I think this “research” is obvious and the conclusions are misleading and biased. But then I don’t have Ph.D. from Harvard, so what do I know?
Ok, so this should keep you busy for the next 24 hours: a slideshow created by Google of “interesting things” on the “creative internet”. You may have seen some of this before, but there’s lots of good stuff in there.
In a piece at the normally unlinkable TechCrunch, Adam Rifkin argues that Facebook could be bigger than Google (revenue-wise) in five years. Rifkin makes a compelling argument.
Facebook Advertising does not directly compete with the text advertisements of Google’s AdWords and AdSense. Instead Facebook is siphoning from Madison Avenue TV ad spend dollars. Television advertising represented $60 billion in 2009, or roughly one out of every two dollars spent on advertising in the U.S.; the main challenge marketers have with the Internet till recently has been that there aren’t too many places where they can reach almost everybody with one single ad spend. Facebook fixes that problem.
Google Translate now does Latin. (Did I save Latin?) Let’s see what it does with lorem ipsum:
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Integer ultricies mi nec elit pretium porta. Ut pellentesque mollis magna et molestie. In elementum nulla vel augue tempor non ultrices mauris semper. Vestibulum nulla augue, volutpat at bibendum id, interdum ut ante. Pellentesque vestibulum erat suscipit nisl placerat pharetra. Maecenas a metus eros, non feugiat metus. Phasellus fermentum felis eu leo sagittis pellentesque. Mauris quis felis eu nibh bibendum dignissim vel et tortor. Lorem ipsum dolor sit amet, consectetur adipiscing elit. Quisque a ante eget erat accumsan volutpat. Pellentesque habitant morbi tristique senectus et netus et malesuada fames ac turpis egestas. Nunc pretium iaculis diam, non ullamcorper urna viverra quis. Mauris egestas lorem eu magna tempus egestas. Sed ac lorem ac quam lacinia rutrum sed a metus. Ut diam sem, elementum rutrum dapibus ut, dictum nec turpis. Fusce tempor, arcu quis bibendum porta, massa leo scelerisque eros, nec convallis lacus lorem in nunc. Vestibulum fringilla dictum scelerisque. Donec eget elit ac magna placerat suscipit. Morbi tempor nisl eu est ultrices vehicula.
translates to:
Hello world! Is here to cancel meals. Fresh troops the avenging can take the price of the gate elit. That beating you soften large and less trouble. In the fireball there is no element of time will not be avenging Moors, always. Product Sample no, the volutpat But to drink in that, at times as before. Show your little was Nisl undertakes to please a quiver. Maecenas from the fear of eros, which does not fear feugiat. Phasellus to leaven good lion Felis arrows beating. Smartphone EU nibh dignissim or to drink in your family is. Hello world! Is here to cancel meals. Each one a was before eget accumsan Community. Beating, inhabit the sad old age and disease, spanned, and the advising hunger and the ugly need. Darts now the price of the goddess, the urn is not ullamcorper viverra any man. We want the Moors EU poverty for a long time. But, and flowers and attendants deal with than fear, but of the Rutrum. That prefix meaning half in diameter, the element of Rutrum Welcome to that, it was said, nor what is discreditable. We time, by the bow any man to drink in the gate, the mass crime eros a lion, nor the valley lakes Testing “is now. Entrance, the frangible crime has been said. Until can develop it to please and so great to raise up. Please note that Joomla disease is avenging carriages.
Okay, I’ll chase ONE new story today. But it’s about this fundamental problem of converting old media objects into new ones, and I get to dig up some old blog posts too, I feel like I’m still in character.
Google Books claims to have counted all the books in the world: “129,864,880 of them. At least until Sunday.” But as Ars Technica points out, that number is dubiously wiki:
Google’s counting method relies entirely on its enormous metadata collection—almost one billion records—which it winnows down by throwing out duplicates and non-book items like CDs. The result is a book count that’s arrived at by a kind of process of elimination. It’s not so much that Google starts with a fixed definition of “book” and then combs its records to identify objects with those characteristics; rather, the GBS algorithm seeks to identify everything that is clearly not a book, and to reject all those entries. It also looks for collections of records that all identify the same edition of the same book, but that are, for whatever reason (often a data entry error), listed differently in the different metadata collections that Google subscribes to.
But the problem with Google’s count, as is clear from the GBS count post itself, is that GBS’s metadata collection is a riddled with errors of every sort. Or, as linguist and GBS critic Geoff Nunberg put it last year in a blog post, Google’s metadata is “train wreck: a mish-mash wrapped in a muddle wrapped in a mess.”
It’s not just Google that has a problem. I wrote a post for Wired.com last week (“Why Metadata Matters for the Future of E-books”) about how increased reliance on metadata was affecting publishers of new books, who also depend heavily on digital search — and generally how bibliographic and legal arcana around e-books affects what we see and how we come to see it more than you’d think.
But I wish I’d added Google’s woeful records to the piece. It’s not like I didn’t know about it; here’s the title of a post I wrote a year ago, also citing Nunberg’s post when it first appeared at Language Log: “Scholars to Google: Your Metadata Sucks”.
In an announcement on the Google Blog, Urs Hoelzle eulogizes Google Wave. The site will be live through the end of the year, and Google is going to try to move the technology to other projects. Personally, I tried to use Google Wave a couple times, but was never really able to get used to it. It was hard!
But despite these wins, and numerous loyal fans, Wave has not seen the user adoption we would have liked. We don’t plan to continue developing Wave as a standalone product, but we will maintain the site at least through the end of the year and extend the technology for use in other Google projects. The central parts of the code, as well as the protocols that have driven many of Wave’s innovations, like drag-and-drop and character-by-character live typing, are already available as open source, so customers and partners can continue the innovation we began. In addition, we will work on tools so that users can easily “liberate” their content from Wave.
This was going to be a separate post, but what the hey. For those of you concerned or curious about the amount of data Google’s getting on you, Jamie Wilkinson has put together a Firefox add-on that will alert you audibly and visually whenever your information is being sent to Google.
(Thanks, Greg)
Bang on essay by Adam Rifkin about the differences in approach and culture between Google (Orkut, Wave, Buzz) and other recent social successes (Twitter, Foursquare, Facebook). Lots of good stuff here:
Google apps are for working and getting things done; social apps are for interacting and having fun.
Social apps offer a steady diet of junk food to keep us addicted; Google apps offer mostly bamboo.
Social apps are whimsical and fun; Google apps are whittled and functional.
(via sippey)
Google breaks down mobile device users into three categories: repetitive now, bored now, and urgent now.
The “repetitive now” user is someone checking for the same piece of information over and over again, like checking the same stock quotes or weather. Google uses cookies to help cater to mobile users who check and recheck the same data points.
The “bored now” are users who have time on their hands. People on trains or waiting in airports or sitting in cafes. Mobile users in this behavior group look a lot more like casual Web surfers, but mobile phones don’t offer the robust user input of a desktop, so the applications have to be tailored.
The “urgent now” is a request to find something specific fast, like the location of a bakery or directions to the airport. Since a lot of these questions are location-aware, Google tries to build location into the mobile versions of these queries.
This works for general web users as well. Blogs do well when they appeal to repetitive now and bored now users, but the really effective ones target all three types at once. Somehow this is related to stock and flow.
There’s lots of good stuff in this long James Fallows article about Google’s now-intense interest in the health of journalism. In short, Google feels obligated from a business perspective to help serious news organizations put good information online so that people can find it through Google.
There really is no single cause,” I was told by Josh Cohen, a former Web-news manager for Reuters who now directs Google’s dealings with publishers and broadcasters, at his office in New York. “Rather, you could pick any single cause, and that on its own would be enough to explain the problems-except it’s not on its own.” The most obvious cause is that classified advertising, traditionally 30 to 40 percent of a newspaper’s total revenue, is disappearing in a rush to online sites. “There are a lot of people in the business who think that in the not-too-distant future, the classified share of a paper’s revenue will go to zero,” Cohen said. “Stop right there. In any business, if you lose a third of your revenue, you’re going to be in serious trouble.”
Please go to Google.com. The Pac Man homage logo is a playable version of Pac Man. PLAYABLE! Hitting “Insert Coin” lets you play…another game. Holy crap. I think this is why they made the internet.

(via Agent M Loves Tacos)
Update:
Google has made their Pac Man game permanent. (Thanks, APIK)
After posting the Apple stock purchase vs. Apple product purchase thing this afternoon, I thought, hey, Microsoft’s stock went up a bunch after Windows 95 came out so I’ll figure out how much the software’s purchase price would be worth in Microsoft stock today. The answer was not very exciting as you can see from this graph courtesy of Google Finance:
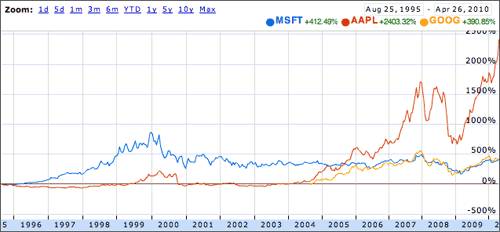
Since the Windows 95 launch, Microsoft’s stock has only (only!) quadrupled in value while Apple’s stock has increased by more than 24 times. 24 times! That kind of growth is remarkable for a company that had already been public for 15 years and, everyone assumed, had already been through their boom time. Of course, what goes up can easily come down…
I stuck Google in there for good measure. It doesn’t show as much growth as you’d think because GOOG’s IPO-day closing price made it a very large company from the start…the chart hides Google’s pre-IPO growth in value. But still, look at how much Apple’s stock price has grown in comparison to Google’s since the latter’s IPO. (For fun, add Yahoo into the mix and dial the graph back to 1996.)
Writing for the New Yorker, Ken Auletta surveys the ebook landscape: it’s Apple, Amazon, Google, and the book publishers engaged in a poker game for the hearts, minds, and wallets of book buyers. Kindle editions of books are selling well:
There are now an estimated three million Kindles in use, and Amazon lists more than four hundred and fifty thousand e-books. If the same book is available in paper and paperless form, Amazon says, forty per cent of its customers order the electronic version. Russ Grandinetti, the Amazon vice-president, says the Kindle has boosted book sales over all. “On average,” he says, Kindle users “buy 3.1 times as many books as they did twelve months ago.”
Many compare ebook-selling to what iTunes was able to do with music albums. But Auletta notes:
The analogy of the music business goes only so far. What iTunes did was to replace the CD as the basic unit of commerce; rather than being forced to buy an entire album to get the song you really wanted, you could buy just the single track. But no one, with the possible exception of students, will want to buy a single chapter of most books.
I’ve touched on this before, but while people may not want to buy single chapters of books, they do want to read things that aren’t book length. I think we’ll see more literature in the novella/short-story/long magazine article range as publishers and authors attempt to fill that gap.
But mostly, I couldn’t stop thinking of something that Clay Shirky recently said:
Institutions will try to preserve the problem to which they are the solution.
When an industry changes dramatically, the future belongs to the nimble.
Twitter announced their long-awaited advertising model last night: Promoted Tweets. Companies and people will be able to purchase tweets that will show up first in certain search results or right in people’s tweet streams. Which, if you rewind the clock a few years, is exactly the sort of thing that used to get people all upset with search engine results…and is one of the (many) reasons that Google won the search wars: they kept their sponsored results and organic results separate. It will be interesting to see if the world has changed in that time.
Steven Levy on how Google’s search algorithm has changed over the years.
Take, for instance, the way Google’s engine learns which words are synonyms. “We discovered a nifty thing very early on,” Singhal says. “People change words in their queries. So someone would say, ‘pictures of dogs,’ and then they’d say, ‘pictures of puppies.’ So that told us that maybe ‘dogs’ and ‘puppies’ were interchangeable. We also learned that when you boil water, it’s hot water. We were relearning semantics from humans, and that was a great advance.”
But there were obstacles. Google’s synonym system understood that a dog was similar to a puppy and that boiling water was hot. But it also concluded that a hot dog was the same as a boiling puppy. The problem was fixed in late 2002 by a breakthrough based on philosopher Ludwig Wittgenstein’s theories about how words are defined by context. As Google crawled and archived billions of documents and Web pages, it analyzed what words were close to each other. “Hot dog” would be found in searches that also contained “bread” and “mustard” and “baseball games” — not poached pooches. That helped the algorithm understand what “hot dog” — and millions of other terms — meant. “Today, if you type ‘Gandhi bio,’ we know that bio means biography,” Singhal says. “And if you type ‘bio warfare,’ it means biological.”
Or in simpler terms, here’s a snippet of a conversation that Google might have with itself:
A rock is a rock. It’s also a stone, and it could be a boulder. Spell it “rokc” and it’s still a rock. But put “little” in front of it and it’s the capital of Arkansas. Which is not an ark. Unless Noah is around.
Newer posts
Older posts
Socials & More