Ethics books gets stolen more often than
Ethics books gets stolen more often than non-ethics books. “Missing books as a percentage of those off shelf were 8.7% for ethics, 6.9% for non-ethics, for an odds ratio of 1.25 to 1.” (via mr)
This site is made possible by member support. 💞
Big thanks to Arcustech for hosting the site and offering amazing tech support.
When you buy through links on kottke.org, I may earn an affiliate commission. Thanks for supporting the site!
kottke.org. home of fine hypertext products since 1998.
Beloved by 86.47% of the web.
Ethics books gets stolen more often than non-ethics books. “Missing books as a percentage of those off shelf were 8.7% for ethics, 6.9% for non-ethics, for an odds ratio of 1.25 to 1.” (via mr)
Nicholas Felton’s personal annual report for 2006. “Disclaimer: Alcoholic beverages were consumed during the collection of this data and the author acknowledges that the occasional drink may have gone unrecorded.” Here’s the one for 2005. LOVE this.
Proposal from Language Log: scientific and technical papers should come with an executable “recipe” for generating numbers, graphs, and tables from published data.
As many of you don’t know, I’ve been working less-than-diligently1 on a project with the eventual goal of adding tags to kottke.org. I posted some early results back in August of 2005. The other day, I started thinking about how tags could help people get a sense of what’s been talked about recently on the site, like Flickr’s listing of hot tags. I started by compiling a list of tags from the last 200 entries and ordering them by how many times they were used over that period. Here is the top 20 (with # of instances in parentheses)
photography (33), books (26), art (26), science (22), tv (21), movies (21), lists (20), video (17), nyc (16), weblogs (15), design (14), interviews (13), bestof (13), business (12), thewire (12), food (11), sports (11), games (10), language (10), music (9)
The items in bold also appear in the top 50 of the all-time popular tags, so obviously this list isn’t telling us anything new about what’s going on around here. To weed those always-popular tags from the list, I compared the recent frequency of each tag with its all-time frequency and came up with a list of tags that are freakishly popular right now compared to how popular they usually are. Call this list a measure of the popularity acceleration of each tag. The top 20:
blindside (3), pablopicasso (3), ghostmap (3), davidsimon (5), poptech2006 (4), thewire (12), andywarhol (3), michaellewis (4), education (4), youtube (4), richarddawkins (5), realestate (3), crime (8), working (8), school (3), dvd (4), georgewbush (4), stevenjohnson (5), writing (4), photoshop (3)
(Note: I also removed tags with less than three instances from this list and the ones below.) Now we’re getting somewhere. None of these appear in the top 50 all-time list. But it’s still not that accurate a list of what’s been going on here recently. I’ve posted 3 times about Photoshop, but you can’t discount entirely the 33 posts about photography. What’s needed is a mix of the two lists: generally popular tags that are also popular right now (first list) + generally unpopular tags that are popular right now (second list). So I blended the two lists together in different proportions:
75% recent / 25% all-time:
davidsimon (5), poptech2006 (4), ghostmap (3), pablopicasso (3), blindside (3), thewire (12), andywarhol (3), michaellewis (4), education (4), photography (33), art (26), youtube (4), tv (21), richarddawkins (5), books (26), crime (8), video (17), working (8), realestate (3), science (22)
67% recent / 33% all-time:
davidsimon (5), poptech2006 (4), pablopicasso (3), ghostmap (3), blindside (3), thewire (12), andywarhol (3), photography (33), art (26), michaellewis (4), education (4), tv (21), books (26), youtube (4), video (17), science (22), richarddawkins (5), crime (8), movies (21), lists (20)
50% recent / 50% all-time:
thewire (12), davidsimon (5), photography (33), poptech2006 (4), blindside (3), ghostmap (3), pablopicasso (3), art (26), books (26), tv (21), science (22), movies (21), lists (20), andywarhol (3), video (17), michaellewis (4), education (4), nyc (16), weblogs (15), crime (8)
25% recent / 75% all-time:
photography (33), art (26), books (26), tv (21), science (22), movies (21), lists (20), thewire (12), video (17), nyc (16), weblogs (15), davidsimon (5), poptech2006 (4), design (14), interviews (13), bestof (13), blindside (3), ghostmap (3), pablopicasso (3), business (12)
The 75%-66% recent lists look like a nice mix of the newly & perenially popular and a fairly accurate representation of the last 3 weeks of posts on kottke.org.
Digression for programmers and math enthusiastists only: I’m curious to know how others would have handled this issue. I approached the problem in the most straighforward manner I could think of (using simple algebra) and the results are pretty good, but it seems like an approach that makes use an equation that approximates the distribution of the popularity of the tags (which roughly follows a power law curve) would work better. Here’s what I did for each tag (using the nyc tag as an example):
# of recent entries: 300
# of total entries: 3399
# of recent instances of the nyc tag: 16
# of total instances of the nyc tag: 247
# of instances of the most frequent recent tag: 33
# of instances of the most frequent tag, all-time: 272
Calculate the recent and all-time frequencies of the nyc tag:
16/300 = 0.0533
247/3399 = 0.0726
Then divide the recent frequency by the all-time frequency to get the popularity acceleration:
0.0533/0.0726 = 0.7342
That’s how much more popular the nyc tag is now than it has been all-time. In other words, the nyc tag is 0.7342 times as popular over the last 300 entries as it has been overall…~1/4 less popular than it usually is. To get the third list with the 75% emphasis on population acceleration and 25% on all-time popularity, I stated by normalizing the popularity acceleration and all-time frequency by dividing the nyc tag values by the top value of the group in each case (11.33 is the popularity acceleration of the blindside tag and 0.11 is the recent frequency of the photography tag (33/300)):
0.7342/11.33 = 0.0647
0.0533/0.11 = 0.4845
So, the nyc tag has a popularity acceleration of 0.0647 times that of the blindside tag and has a recent frequency that is 0.4845 times that of the most popular recent tag. Then:
0.0647*0.75 + 0.4845*0.25 = 0.1696
Calculate this number for each recent tag, rank them from highest to lowest, and you get the third list above. Now, it seems to me that I may have fudged something in the last two steps, but I’m not exactly sure. And if I did, I don’t know what got fudged. Any help or insight would be appreciated.
[1] Great artists ship. Mediocre artists ship slowly. ↩
Suroweicki explans why ever-rising housing prices may be deceiving. “If you control for inflation and quality…real home prices barely budged between the eighteen-nineties and the nineteen-nineties. The idea that housing prices have nowhere to go but up is, in other words, a statistical illusion.”
Netflix, the online DVD rental company, recently released a bunch of their ratings data with the offer of a $1 million prize to anyone who could use that data to make a better movie recommendation system. On the forum for the prize, someone noted that the top 5 most frequently rated movies on Netflix were not particularly popular or critically acclaimed (via fakeisthenewreal):
1. Miss Congeniality
2. Independence Day
3. The Patriot
4. The Day After Tomorrow
5. Pirates of the Caribbean
That led another forum participant to analyze the data and he found some interesting things. The most intriguing result is a list of the movies that Netflix users either really love or really hate:
1. The Royal Tenenbaums
2. Lost in Translation
3. Pearl Harbor
4. Miss Congeniality
5. Napoleon Dynamite
6. Fahrenheit 9/11
7. The Patriot
8. The Day After Tomorrow
9. Sister Act
10. Armageddon
11. Kill Bill: Vol. 1
12. Independence Day
13. Sweet Home Alabama
14. Titanic
15. Gone in 60 Seconds
16. Twister
17. Anchorman: The Legend of Ron Burgundy
18. Con Air
19. The Fast and the Furious
20. Dirty Dancing
21. Troy
22. Eternal Sunshine of the Spotless Mind
23. The Passion of the Christ
24. How to Lose a Guy in 10 Days
25. Pretty Woman
So what makes these movies so contentious? Generalizing slightly (*cough*), the list is populated with three basic kinds of movies:
Misunderstood masterpieces / cult favorites (Royal Tenenbaums, Kill Bill, Eternal Sunshine)
Action movies (Pearl Harbor, Armageddon, Fast and the Furious)
Chick flicks (Sister Act, Sweet Home Alabama, Miss Congeniality)
The thing that all those kinds of movies have in common is that if you’re outside of the intended audience for a particular movie, you probably won’t get it. That means that if you hear about a movie that’s highly recommended within a certain group and you’re not in that group, you’re likely to hate it. In some ways, these are movies intended for a narrow audience, were highly regarded within that audience, tried to cross over into wider appeal, and really didn’t make it.
Titanic is really the only outlier on the list…massively popular among several different groups of people and critically well-regarded as well. But I know quite a few people who absolutely hate this movie — the usual complaints are a) chick flick, b) James Cameron’s heavy-handedness, and c) reaction to the huge success of what is perceived to be a marginally entertaining, middling quality film.
BTW, here are the movies on that list that fit into my “love it” category:
The Royal Tenenbaums
Lost in Translation
Napoleon Dynamite
The Day After Tomorrow
Kill Bill: Vol. 1
Titanic
Eternal Sunshine of the Spotless Mind
Where do Craigslist’s Missed Connections occur in NYC? Gawker has the breakdown by location and subway line.
A recent study concludes that in terms of life expectancy, there are eight different Americas, all with differing levels of health. “In 2001, 15-year-old blacks in high-risk city areas were three to four times more likely than Asians to die before age 60, and four to five times more likely before age 45. In fact, young black men living in poor, high-crime urban America have death risks similar to people living in Russia or sub-Saharan Africa.” If I’m reading this right, it’s interesting that geography or income doesn’t have that big of an impact on the life expectancy of Asians; it’s their Asian-ness (either cultural, genetic, or both) that’s the key factor. Here’s the study itself. (via 3qd)
Forecast Advisor tracks how accurate the major weather forecasting companies are in predicting temperature and precipitation. Results vary based on what part of the country you’re in (the weather in Honoulu is easier to forecast than that of Minneapolis), but overall the forecasters have an accuracy rate of around 72%.
Graph of American house values from 1890 to the present. You can’t miss the sheer cliff starting in 1997. Houses have also gotten bigger over time. It would be interesting to see the same graph in price/square feet. (via ben hyde)
Fascinating charts of how the US Senate votes on issues from a liberal-conservative perspective and a social issues perspective. More charts here. You’ll notice that the lines on the graphs are mostly straight up and down which means “it’s all economic; all the noise about social issues never actually flows thru into the legislative agenda.” That is, the Senate decides issues, even social issues, based mostly on economics.
Rethinking Moneyball. Jeff Passan looks at how the Oakland A’s 2002 draft class, immortalized in Michael Lewis’ Moneyball, has done since then. “It is not so much scouts vs. stats anymore as it is finding the right balance between information gleaned by scouts and statistical analyses. That the Moneyball draft has produced three successful big-league players, a pair of busts and two on the fence only adds to its polarizing nature.” Richard Van Zandt did a more extensive analysis back in April.
Kevin Burton looks at the Technorati “data” and discovers that since the number of daily postings is growing linearly, the number of active blogs is probably growing lineary too…which means that the exponential growth of the blogosphere touted repeatedly by Technorati and parroted by mainstream media outlets is actually the growth of dead blogs.
An enormous amount of statistics about the book industry. “58% of the US adult population never reads another book after high school.”
People are trying to figure out why the Alexa statistics for a bunch of sites (including kottke.org) jumped sharply in mid-April. I don’t buy the Digg explanation (for one thing, the timeline is off by a month)…it’s gotta be some partnership or something that kicked in. Or how about Alexa’s “facelift” on April 11?
A quick study shows that stocks of simply named companies do better than those of more complexly named companies. Even companies with pronounceable ticker symbols did better than those with unpronounceable symbols.
The Junk Charts blog searches for example of crappy graphs and charts in the media. (via do)
Demographic charts for New York City using data from 1790 to the present.
Benford’s Law describes a curious phenomenon about the counterintuitive distribution of numbers in sets of non-random data:
A phenomenological law also called the first digit law, first digit phenomenon, or leading digit phenomenon. Benford’s law states that in listings, tables of statistics, etc., the digit 1 tends to occur with probability ~30%, much greater than the expected 11.1% (i.e., one digit out of 9). Benford’s law can be observed, for instance, by examining tables of logarithms and noting that the first pages are much more worn and smudged than later pages (Newcomb 1881). While Benford’s law unquestionably applies to many situations in the real world, a satisfactory explanation has been given only recently through the work of Hill (1996).
I first heard of Benford’s Law in connection with the IRS using it to detect tax fraud. If you’re cheating on your taxes, you might fill in amounts of money somewhat at random, the distribution of which would not match that of actual financial data. So if the digit “1” shows up on Al Capone’s tax return about 15% of the time (as opposed to the expected 30%), the IRS can reasonably assume they should take a closer look at Mr. Capone’s return.
Since I installed Movable Type 3.15 back in March 2005, I have been using its “post to the future” option pretty regularly to post my remaindered links…and have been using it almost exclusively for the last few months[1]. That means I’m saving the entries in draft, manually changing the dates and times, and then setting the entries to post at some point in the future. For example, an entry with a timestamp like “2006-02-20 22:19:09” when I wrote the draft might get changed to something like “2006-02-21 08:41:09” for future posting at around 8:41 am the next morning. The point is, I’m choosing basically random numbers for the timestamps of my remaindered links, particularly for the hours and minutes digits. I’m “cheating”…committing post timestamp fraud.
That got me thinking…can I use the distribution of numbers in these post timestamps to detect my cheating? Hoping that I could (or this would be a lot of work wasted), I whipped up a MT template that produced two long strings of numbers: 1) one of all the hours and minutes digits from the post timestamps from May 2005 to the present (i.e. the cheating period), 2) and one of all the hours and minutes digits from Dec 2002 - Jan 2005 (i.e. the control group). Then I used a PHP script to count the numbers in each string, dumped the results into Excel, and graphed the two distributions together. And here’s what they look like, followed by a table of the values used to produce the chart:
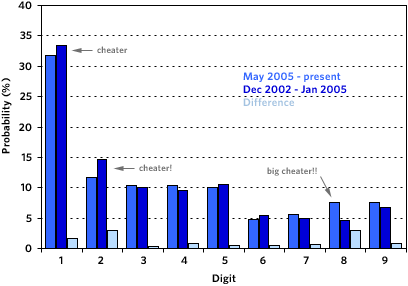
| Digit | 5/05-now | 12/02-1/05 | Difference |
| 1 | 31.76% | 33.46% | 1.70% |
| 2 | 11.76% | 14.65% | 2.89% |
| 3 | 10.30% | 9.96% | 0.34% |
| 4 | 10.44% | 9.58% | 0.86% |
| 5 | 10.02% | 10.52% | 0.51% |
| 6 | 4.83% | 5.40% | 0.57% |
| 7 | 5.66% | 4.96% | 0.70% |
| 8 | 7.62% | 4.65% | 2.97% |
| 9 | 7.60% | 6.81% | 0.79% |
As expected, 1 & 2 show up less than they should during the cheating period, but not overly so[2]. The real fingerprint of the crime lies with the 8s. The number 8 shows up during the cheating period ~64% more than expected. After thinking about it for awhile, I came up with an explanation for the abundance of 8s. I often schedule posts between 8am-9am so that there’s stuff on the site for the early-morning browse and I usually finish off the day with something between 6pm-7pm (18:00 - 19:00). Not exactly the glaring evidence I was expecting, but you can still tell.
The obvious next question is, can this technqiue be utilized for anything useful? How about detecting comment, trackback. or ping spam? I imagine IPs and timestamps from these types of spam are forged to at least some extent. The difficulties are getting enough data to be statistically significant (one forged timestamp isn’t enough to tell anything) and having “clean” data to compare it against. In my case, I knew when and where to look for the cheating…it’s unclear if someone who didn’t know about the timestamp tampering would have been able to detect it. I bet companies with services that deal with huge amounts of spam (Gmail, Yahoo Mail, Hotmail, TypePad, Technorati) could use this technique to filter out the unwanted emails, comments, trackbacks, or pings…although there’s probably better methods for doing so.
[1] I’ve been doing this to achieve a more regular publishing schedule for kottke.org. I typically do a lot of work in the evening and at night and instead of posting all the links in a bunch from 10pm to 1am, I space them out over the course of the next day. Not a big deal because increasing few of the links I feature are time-sensitive and it’s better for readers who check back several times a day for updates…they’ve always got a little something new to read.
[2] You’ll also notice that the distributions don’t quite follow Benford’s Law either. Because of the constraints on which digits can appear in timestamps (e.g. you can never have a timestamp of 71:95), some digits appear proportionally more or less than they would in statistical data. Here’s the distribution of digits of every possible time from 00:00 to 23:59:
1 - 25.33
2 - 17.49
3 - 12.27
4 - 10.97
5 - 10.97
6 - 5.74
7 - 5.74
8 - 5.74
9 - 5.74
Fun analysis of a moviegoer’s six years of ticket stubs. You can see the ticket prices rise over the years, but what’s really interesting is the correspondence between the ticket price and his opinion of the movie…he ended up paying more for the movies he really liked.
Interesting graph comparing the size of new homes and the obesity rate in America (which seem to track quite closely since 1995), prompting the question, are Americans growing to fit their environment? Relatedly, Bernard-Henri Levy on American obesity: “The obesity of the body is a metaphor of another obesity. There is a tendency in America to believe that the bigger the better for everything — for churches, cities, malls, companies and campaign budgets. There’s an idolatry of bigness.”
The Baseball Visualization Tool was designed to help managers answer the question: should the pitcher be pulled from the game? Handy charts and pie graphs give managers an at-a-glance view of how much trouble the current pitcher is in. I wonder what TBVT would have told Grady Little about Pedro at the end of Game 7 of the 2003 ALCS?
There’s been lots of talk on the web lately about Digg being the new Slashdot. Two months ago, a Digg reader noted that according to Alexa, Digg’s traffic was catching up to that of Slashdot, even though Slashdot has been around for several years and Digg is just over a year old. The brash newcomer vs. the reigning champ, an intriguing matchup.
Last weekend, a piece on kottke.org (50 Fun Things to Do With Your iPod) was featured on Digg and Slashdot[1] and the experience left behind some data that presents a interesting comparison to the Alexa data.
On 1/7 at around 11:00pm ET (a Saturday night), the 50 Things/iPod link appeared on Digg’s front page. It’s unclear exactly what time the link fell off the front page, but from the traffic pattern on my server, it looks like it lasted until around 2am Sunday night (about 3 hours). As of 10pm ET on 1/11, the story had been “dugg” 1387 times[2], garnered 65 comments, and had sent ~20,000 people to kottke.org.
On 1/8 at around 5pm ET (a Sunday afternoon), the 50 Things/iPod link appeared on Slashdot’s front page and was up there for around 24 hours. As of 10pm ET on 1/11, the story has elicited 254 comments and sent ~84,100 people to kottke.org.
Here’s a graph of my server’s traffic (technically, it’s a graph of the bandwidth out in megabits/second) during the Digg and Slashdot events. I’ve overlaid the Digg trend on the Slashdot one so you can directly compare them:
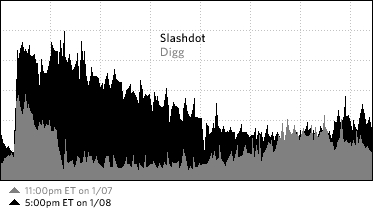
That’s roughly 18 hours of data…and the scales of the two trends are the same. Here’s a graph that shows the two events together on the same trend, along with a “baseline” traffic graph of what the bandwidth approximately would have been had neither site linked to kottke.org:
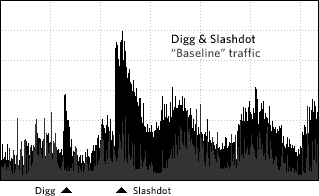
That’s about 4.5 days of data. Each “bump” on the baseline curve is a day[3].
The two events are separated by just enough time that it’s possible to consider them more or less separately and make some interesting observations. Along with some caveats, here’s what the data might be telling us:
In terms of comparing this with the Alexa data, it’s not a direct comparison because they’re measuring visitors to Digg and Slashdot, and I’m measuring (roughly) visitors from each of those sites. From the kottke.org data, you can infer how many people visit each site by how many people visited from each site initially…the bandwidth burst from Slashdot was roughly about 1.8 times as large as Digg’s. That’s actually almost exactly what Alexa shows (~1.8x).
But over a period of about 4 days, Slashdot has sent more than 4 times the number of visitors to kottke.org than Digg — despite a 18-hour headstart for Digg — and the aftershock for Slashdot is much larger and prolonged. It’s been four days since the Slashdotting and kottke.org is still getting 15,000 more visitors a day than usual. This indicates that although Digg may rapidly be catching up to Slashdot traffic-wise, it has a way to go in terms of influence[4].
Slashdot is far from dying…the site still wields an enormous amount of influence. That’s because it’s been around so long, it’s been big, visible, and influential for so long, and their purpose is provide their audience with 20-25 relevant links/stories each day. The “word-of-mouth” network that Slashdot has built over the years is broad and deep. When a link is posted to Slashdot, not only do their readers see it, it’s posted to other blogs (and from there to other blogs, etc.), forwarded around, etc. And those are well-established pathways.
In contrast, Digg’s network is not quite so broad and certainly less deep…they just haven’t been around as long. Plus Digg has so much flow (links/day) that what influence they do have is spread out over many more links, imparting less to each individual link. (There are quite a few analogies you can use somewhat successfully here…the mafia don who outsmarts a would-be usurper because of his connections and wisdom or the aging rock group that may currently be less popular than the flavor of the month but has collectively had a bigger influence on pop music. But I’ll leave making those analogies as an exercise to the reader.)
What all this suggests is that if you’re really interested in how influence works on the web, just looking at traffic or links doesn’t tell you the whole story and can sometimes be quite misleading. Things like longevity, what the social & linking networks look like, and how sites are designed are also important. The Alexa data suggests that Digg has half the traffic of Slashdot, but that results in 4x the number of visitors from Slashdot and a much larger influence afterwards. The data aside, the Digg link was fun and all but ultimately insignificant. The Slashdot link brought significantly more readers to the site, spurred many other sites to link to it, and appears to have left me with a sizable chunk of new readers. As an online publisher, having those new long-term readers is a wonderful thing.
Anyway, lots of interesting stuff here just from this little bit of data…more questions than conclusions probably. And I didn’t even get into the question of quality that Gene brings up here[5] or the possible effect of RSS[6]. It would be neat to be a researcher at someplace like Google or Yahoo! and be able to look more deeply into traffic flows, link propagation, different network topologies, etc. etc. etc.
[1] The way I discovered the Digging and Slashdotting was that I started getting all sorts of really stupid email, calling me names and swearing. One Slashdot reader called me a “fag” and asked me to stop talking about “gay ipod shit”. The wisdom of the crowds tragedy of the commons indeed.
[2] On Digg, a “digg” is a like a thumbs-up. You dig?
[3] That’s the normal traffic pattern for kottke.org and probably most similar sites…a nearly bell-shaped curve of traffic that is low in the early morning, builds from 8am to the highest point around noon, and declines in the afternoon until it’s low again at night (although not as low as in the morning).
[4] The clever reader will note here that Slashdot got the link from Digg, so who’s influencing who here? All this aftershock business…the Slashdotting is part of the Digg aftershock. To stick with the earthquake analogy though, no one cares about the 5.4 quake if it’s followed up by a 7.2 later in the day.
[5] Ok, twist my arm. Both Digg and Slashbot use the wisdom of crowds to offer content to their readers. Slashdot’s human editors post 25 stories a day suggested by individual readers while Digg might feature dozens of stories on the front page per day, collectively voted there by their readers. In terms of editorial and quality, I am unconvinced that a voting system like Digg’s can produce a quality editorial product…it’s too much of an informational firehose. Bloggers and Slashdot story submitters might like drinking from that hose, but there’s just too much flow (and not enough editing) to make it an everyday, long-term source of information. (You might say that, duh, Digg doesn’t want to be a publication like Slashdot and you’d probably be right, in which case, why are people comparing the two sites in the first place? But still, in terms of influence, editing matters and if Digg wants to keep expanding its influence, it’s gotta deal with that.)
[6] Digg might be more “bursty” than Slashdot because a higher percentage of its audience reads the site via RSS (because they’re younger, grew up with newsreaders in their cribs, etc.). Brighter initial burn but less influence over time.
Chris Anderson has one of the best descriptions I’ve read of collective knowledge systems like Google, Wikipedia, and blogs: they’re probabilistic systems “which sacrifice perfection at the microscale for optimization at the macroscale”.
Table of the odds of dying from various injuries. Looking at statistics like these, I’m always amazed at how worried people are about things that don’t often result in death (fireworks, sharks) and how relatively dangerous automobiles are (see, for example, this list of people on MySpace who have died…many of the deaths on the first two pages involve cars).
Three economists share a cab, getting off at three different destinations. How do they split the fare? For answers, you might look to John Nash or the Talmud.
Gapminder has a ton of stats and resources about human population and development trends. (thx, chris)
Quick overview of increased use of statistics in pro basketball, i.e. the moneyballing of the NBA. More NBA stats madness at 82games.com.

{kind=link}
Socials & More