kottke.org posts about Movable Type
Jason Snell on the supreme uncoolness of Movable Type, the outdated blogging software that powers Snell’s site, Daring Fireball, and also kottke.org.
Regardless, it turns out that software can also be considered uncool, even if it still works. Not only is Movable Type uncool —the equivalent of ’80s hair metal, but the language it’s written in, Perl, is supremely uncool. Like, New Kids on the Block uncool. The razzing John Siracusa takes about being a Perl developer isn’t really because Perl is old, or bad, but because it’s just not what the cool kids are talking about. The world has moved on.
And yet, sometimes that old stuff still works, and is still the best tool for the job.
Movable Type is often maddening and frustrating, but it’s familiar, behaves consistently, and I know it better than any other piece of software. In other words, MT is like a member of my family.
While we’re being all nostalgic, here’s what Gizmodo looked like when it launched:
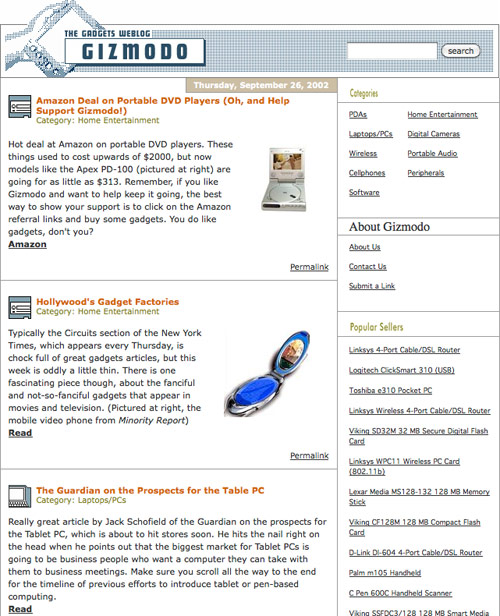
The site, which launched several months before Gawker, was designed & developed by Ben and Mena Trott with the couple’s relatively new blogging software, Movable Type.
Six Apart Japan, Movable Type, and the Six Apart brand will be acquired by Infocom, a Japanese IT firm.
We are happy to announce that Six Apart KK (SAKK), a Japanese subsidiary of SAY Media, has entered into an agreement to be acquired by Infocom, a Japanese IT company, as of February 1, 2011. As part of this transaction, SAKK will assume responsibility for the worldwide Movable Type business, and the Six Apart brand.
We at SAKK are very excited to continue our investment in Movable Type, the Movable Type Open Source project and the worldwide community of developers, publishers and bloggers around the world that use Movable Type.
This depresses me. (via waxy)
1. I recently upgraded the software that powers this site to the most recent version of MT 4. I’ll miss my pimped out copy of MT 3.2 but I’m excited to play with some new-to-me MT 4 features. Between this and my new keyboard, I feel like I just started a new job. Huge 72 pt. THANKS to Six Apart Services né Apperceptive and especially kottke.org patron saint David Jacobs for the excellent support. (Oh, and the iMT plugin for quick iPhone access to MT? Awesome.)
2. Pagination! The front page is now just over a third shorter than it was mere minutes ago. You can continue reading previous entries by pointing your browsing mechanism to page 2 and page 3. That’s one feature down, about 2000 more to go.
Benford’s Law describes a curious phenomenon about the counterintuitive distribution of numbers in sets of non-random data:
A phenomenological law also called the first digit law, first digit phenomenon, or leading digit phenomenon. Benford’s law states that in listings, tables of statistics, etc., the digit 1 tends to occur with probability ~30%, much greater than the expected 11.1% (i.e., one digit out of 9). Benford’s law can be observed, for instance, by examining tables of logarithms and noting that the first pages are much more worn and smudged than later pages (Newcomb 1881). While Benford’s law unquestionably applies to many situations in the real world, a satisfactory explanation has been given only recently through the work of Hill (1996).
I first heard of Benford’s Law in connection with the IRS using it to detect tax fraud. If you’re cheating on your taxes, you might fill in amounts of money somewhat at random, the distribution of which would not match that of actual financial data. So if the digit “1” shows up on Al Capone’s tax return about 15% of the time (as opposed to the expected 30%), the IRS can reasonably assume they should take a closer look at Mr. Capone’s return.
Since I installed Movable Type 3.15 back in March 2005, I have been using its “post to the future” option pretty regularly to post my remaindered links…and have been using it almost exclusively for the last few months[1]. That means I’m saving the entries in draft, manually changing the dates and times, and then setting the entries to post at some point in the future. For example, an entry with a timestamp like “2006-02-20 22:19:09” when I wrote the draft might get changed to something like “2006-02-21 08:41:09” for future posting at around 8:41 am the next morning. The point is, I’m choosing basically random numbers for the timestamps of my remaindered links, particularly for the hours and minutes digits. I’m “cheating”…committing post timestamp fraud.
That got me thinking…can I use the distribution of numbers in these post timestamps to detect my cheating? Hoping that I could (or this would be a lot of work wasted), I whipped up a MT template that produced two long strings of numbers: 1) one of all the hours and minutes digits from the post timestamps from May 2005 to the present (i.e. the cheating period), 2) and one of all the hours and minutes digits from Dec 2002 - Jan 2005 (i.e. the control group). Then I used a PHP script to count the numbers in each string, dumped the results into Excel, and graphed the two distributions together. And here’s what they look like, followed by a table of the values used to produce the chart:
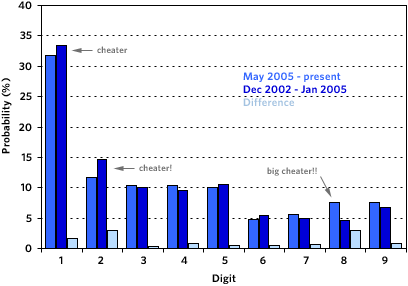
| Digit | 5/05-now | 12/02-1/05 | Difference |
| 1 | 31.76% | 33.46% | 1.70% |
| 2 | 11.76% | 14.65% | 2.89% |
| 3 | 10.30% | 9.96% | 0.34% |
| 4 | 10.44% | 9.58% | 0.86% |
| 5 | 10.02% | 10.52% | 0.51% |
| 6 | 4.83% | 5.40% | 0.57% |
| 7 | 5.66% | 4.96% | 0.70% |
| 8 | 7.62% | 4.65% | 2.97% |
| 9 | 7.60% | 6.81% | 0.79% |
As expected, 1 & 2 show up less than they should during the cheating period, but not overly so[2]. The real fingerprint of the crime lies with the 8s. The number 8 shows up during the cheating period ~64% more than expected. After thinking about it for awhile, I came up with an explanation for the abundance of 8s. I often schedule posts between 8am-9am so that there’s stuff on the site for the early-morning browse and I usually finish off the day with something between 6pm-7pm (18:00 - 19:00). Not exactly the glaring evidence I was expecting, but you can still tell.
The obvious next question is, can this technqiue be utilized for anything useful? How about detecting comment, trackback. or ping spam? I imagine IPs and timestamps from these types of spam are forged to at least some extent. The difficulties are getting enough data to be statistically significant (one forged timestamp isn’t enough to tell anything) and having “clean” data to compare it against. In my case, I knew when and where to look for the cheating…it’s unclear if someone who didn’t know about the timestamp tampering would have been able to detect it. I bet companies with services that deal with huge amounts of spam (Gmail, Yahoo Mail, Hotmail, TypePad, Technorati) could use this technique to filter out the unwanted emails, comments, trackbacks, or pings…although there’s probably better methods for doing so.
[1] I’ve been doing this to achieve a more regular publishing schedule for kottke.org. I typically do a lot of work in the evening and at night and instead of posting all the links in a bunch from 10pm to 1am, I space them out over the course of the next day. Not a big deal because increasing few of the links I feature are time-sensitive and it’s better for readers who check back several times a day for updates…they’ve always got a little something new to read.
[2] You’ll also notice that the distributions don’t quite follow Benford’s Law either. Because of the constraints on which digits can appear in timestamps (e.g. you can never have a timestamp of 71:95), some digits appear proportionally more or less than they would in statistical data. Here’s the distribution of digits of every possible time from 00:00 to 23:59:
1 - 25.33
2 - 17.49
3 - 12.27
4 - 10.97
5 - 10.97
6 - 5.74
7 - 5.74
8 - 5.74
9 - 5.74
Update: I fucked up on this post and you should reread it if you’ve read it before. After reading this post by Niall Kennedy, I checked and found that I have mentioned or linked to the site for Freakonomics 5 times (1 2 3 4 5), not 13. The other 8 times, I either linked to a post on the Freakonomics blog that was unrelated to the book, had the entry tagged with “freakonomics” (tags are not yet exposed on my site and can’t be crawled by search engines), or I used the word “Freakonomists”, not “Freakonomics”. Bottom line: the NY Times listing is still incorrect, Google and Yahoo picked up all the posts where I actually mentioned “Freakonomics” in the text of the post but missed the 2 links to freakonomics.com, Google Blog Search got 2/3 (& missed the 2 links), Technorati got 1/3 (& missed the 2 links), and IceRocket, Yahoo Blog Search, BlogPulse, & Bloglines whiffed entirely. Steven Levitt would be very disappointed in my statistical fact-checking skills right now. :(
I wish Niall had emailed me about this instead of posting it on his site, but I guess that’s how weblogs work, airing dirty laundry instead of trying to get it clean. Fair enough…I’ve publicly complained about the company he works for (Technorati) instead of emailing someone at the company about my concerns, so maybe he had a right to hit back. Perhaps a little juvenile on both our parts, I’d say. (Oh, and I turned off the MT search thing that Niall used to check my work. I’m not upset he used it, but I’m irritated that it seems to be on by default in MT…I never intended for that search interface to be public.)
———
The NY Times recently released their list of the most blogged about books of 2005. Their methodology in compiling the list:
This list links to a selection of Web posts that discuss some of the books most frequently mentioned by bloggers in 2005. The books were selected by conducting an automated survey of 5,000 of the most-trafficked blogs.
Unsurprisingly, the top spot on the list went to Freakonomics. I remembered mentioning the book several times on my site (including this interview with author Steven Levitt around the release of the book), so I checked out the citations they had listed for it. According to the Times, Freakonomics was cited by 125 blogs, but not once by kottke.org, a site that by any measure is one of the most-visited blogs out there.[1] A quick search in my installation of Movable Type yielded 13 5 mentions of the book on kottke.org in the last 9 months. I had also mentioned Blink, Harry Potter, Getting Things Done, Collapse, The Wisdom of Crowds, The Singularity is Near, and State of Fear, all of which appear in the top 20 of the Times’ list and none of which are cited by the Times as having been mentioned on kottke.org in 2005.
I chalked this up to a simple error of omission, but then I started checking around some more. Google’s main index returned only three distinct mentions of Freakonomics on kottke.org. Google Blog Search returned two results. Yahoo: 3 results (0 results on Yahoo’s blog search). Technorati only found one result (I’m not surprised). Many of the blog search services don’t even let you search by site, so IceRocket, BlogPulse, and Bloglines were of no help. (See above for corrections.) I don’t know where the Times got their book statistics from, but it was probably from one of these sites (or a similar service).
Granted this is just one weblog[2], which I only checked into because I’m the author, but it’s not like kottke.org is hard to find or crawl. The markup is pretty good [3], fairly semantic, and hasn’t changed too much for the past two years. The subject in question is not off-topic…I post about books all the time. And it’s one of the more visible weblogs out there…lots of links in to the front page and specific posts and a Google PR of 8. So, my point here is not “how dare the Times ignore my popular and important site!!!” but is that the continuing overall suckiness of searching blogs is kind of amazing and embarrassing given the seemingly monumental resources being applied to the task. It’s forgivable that the Times would not have it exactly right (especially if they’re doing the crawling themselves), but when companies like Technorati and Google are setting themselves up as authorities on how large the blogosphere is, what books and movies people are reading/watching, and what the hot topics online are but can’t properly catalogue the most obvious information out there, you’ve got to wonder a) how good their data really is, and b) if what they are telling us is actually true.
[1] Full disclosure: I am the author of kottke.org.
[2] This is an important point…these observations are obviously a starting point for more research about this. But this one hole is pretty gaping and fits well with what I’ve observed over the past several months trying to find information on blogs using search engines.
[3] I say only pretty good because it’s not validating right now because of entity and illegal character errors, which I obviously need to wrestle with MT to correct at some point. But the underlying markup is solid.
QuotationsBook offers its quotations and search results via RSS. If someone were to write a plug-in for Movable Type for this, you could display related quotations alongside blog posts using tags (e.g. tag an entry with “friends” and you get a quotation about friends). Cool.
Socials & More