kottke.org posts about artificial intelligence



For his Roman Emperor Project, Daniel Voshart (whose day job includes making VR sets for Star Trek: Discovery) used a neural-net tool and images of 800 sculptures to create photorealistic portraits of every Roman emperor from 27 BCE to 285 ACE. From the introduction to the project:
Artistic interpretations are, by their nature, more art than science but I’ve made an effort to cross-reference their appearance (hair, eyes, ethnicity etc.) to historical texts and coinage. I’ve striven to age them according to the year of death — their appearance prior to any major illness.
My goal was not to romanticize emperors or make them seem heroic. In choosing bust / sculptures, my approach was to favor the bust that was made when the emperor was alive. Otherwise, I favored the bust made with the greatest craftsmanship and where the emperor was stereotypically uglier — my pet theory being that artists were likely trying to flatter their subjects.
Some emperors (latter dynasties, short reigns) did not have surviving busts. For this, I researched multiple coin depictions, family tree and birthplaces. Sometimes I created my own composites.
You can buy a print featuring the likenesses of all 54 emperors on Etsy.
See also Hand-Sculpted Archaeological Reconstructions of Ancient Faces and The Myth of Whiteness in Classical Sculpture.
Have you ever wanted to hear Jay Z rap the “To Be, Or Not To Be” soliloquy from Hamlet? You are in luck:
What about Bob Dylan singing Britney Spears’ “…Baby One More Time”? Here you go:
Bill Clinton reciting “Baby Got Back” by Sir Mix-A-Lot? Yep:
And I know you’re always wanted to hear six US Presidents rap NWA’s “Fuck Tha Police”. Voila:
This version with the backing track is even better. These audio deepfakes were created using AI:
The voices in this video were entirely computer-generated using a text-to-speech model trained on the speech patterns of Barack Obama, Ronald Reagan, John F. Kennedy, Franklin Roosevelt, Bill Clinton, and Donald Trump.
The program listens to a bunch of speech spoken by someone and then, in theory, you can provide any text you want and the virtual Obama or Jay Z can speak it. Some of these are more convincing than others — with a bit of manual tinkering, I bet you could clean these up enough to make them convincing.
Two of the videos featuring Jay Z’s synthesized voice were forced offline by a copyright claim from his record company but were reinstated. As Andy Baio notes, these deepfakes are legally interesting:
With these takedowns, Roc Nation is making two claims:
1. These videos are an infringing use of Jay-Z’s copyright.
2. The videos “unlawfully uses an AI to impersonate our client’s voice.”
But are either of these true? With a technology this new, we’re in untested legal waters.
The Vocal Synthesis audio clips were created by training a model with a large corpus of audio samples and text transcriptions. In this case, he fed Jay-Z songs and lyrics into Tacotron 2, a neural network architecture developed by Google.
It seems reasonable to assume that a model and audio generated from copyrighted audio recordings would be considered derivative works.
But is it copyright infringement? Like virtually everything in the world of copyright, it depends-on how it was used, and for what purpose.
Celebrity impressions by people are allowed, why not ones by machines? It’ll be interesting to see where this goes as the tech gets better.
This deepfake video of Back to the Future that features Robert Downey Jr. & Tom Holland as Doc Brown & Marty McFly is so convincing that I almost want to see an actual remake with those actors. (Almost.)
They really should have deepfaked Zendaya into the video as Lorraine for the cherry on top. Here’s an earlier effort with Holland as Marty that’s not as good.
Collaborating with the team at Conde Nast Entertainment and Vogue, my pal Nicole He trained an AI program to interview music superstar Billie Eilish. Here are a few of the questions:
Who consumed so much of your power in one go?
How much of the world is out of date?
Have you ever seen the ending?
This is a little bit brilliant. The questions are childlike in a way, like something a bright five-year-old would ask a grownup, perceptive and nonsensical (or even Dr. Seussical) at the same time. As He says:
What I really loved hearing Billie say was that human interviewers often ask the same questions over and over, and she appreciated that the AI questions don’t have an agenda in the same way, they’re not trying to get anything from her.
I wonder if there’s something that human interviewers can learn from AI-generated questions — maybe using them as a jumping off point for their own questions or asking more surprising or abstract questions or adapting the mentality of the childlike mind.
See also Watching Teen Superstar Billie Eilish Growing Up.
When Neil Armstrong and Buzz Aldrin landed safely on the Moon in July 1969, President Richard Nixon called them from the White House during their moonwalk to say how proud he was of what they had accomplished. But in the event that Armstrong and Aldrin did not make it safely off the Moon’s surface, Nixon was prepared to give a very different sort of speech. The remarks were written by William Safire and recorded in a memo called In Event of Moon Disaster.
Fifty years ago, not even Stanley Kubrick could have faked the Moon landing. But today, visual effects and techniques driven by machine learning are so good that it might be relatively simple, at least the television broadcast part of it.1 In a short demonstration of that technical supremacy, a group from MIT has created a deepfake version of Nixon delivering that disaster speech. Here are a couple of clips from the deepfake speech:
Fate has ordained that the men who went to the moon to explore in peace will stay on the moon to rest in peace.
The full film is being shown at IDFA DocLab in Amsterdam and will make its way online sometime next year.
The implications of being able to so convincingly fake the televised appearance of a former US President are left as an exercise to the reader. (via boing boing)
Update: The whole film is now online. (thx, andy)
In a recent issue of Why is this interesting?, Noah Brier collects a number of perspectives on whether (and by whom) a work created by an artificial intelligence can be copyrighted.
But as I dug in a much bigger question emerged: Can you actually copyright work produced by AI? Traditionally, the law has been that only work created by people can receive copyright. You might remember the monkey selfie copyright claim from a few years back. In that case, a photographer gave his camera to a monkey who then snapped a selfie. The photographer then tried to claim ownership and PETA sued him to try to claim it back for the monkey. In the end, the photograph was judged to be in the public domain, since copyright requires human involvement. Machines, like monkeys, can’t own work, but clearly something made with the help of a human still qualifies for copyright. The question, then, is where do we draw the line?
In the Guardian, former astrologer Felicity Carter writes about how fortune telling really works and why she had to quit.
I also learned that intelligence and education do not protect against superstition. Many customers were stockbrokers, advertising executives or politicians, dealing with issues whose outcomes couldn’t be controlled. It’s uncertainty that drives people into woo, not stupidity, so I’m not surprised millennials are into astrology. They grew up with Harry Potter and graduated into a precarious economy, making them the ideal customers.
What broke the spell for me was, oddly, people swearing by my gift. Some repeat customers claimed I’d made very specific predictions, of a kind I never made. It dawned on me that my readings were a co-creation — I would weave a story and, later, the customer’s memory would add new elements. I got to test this theory after a friend raved about a reading she’d had, full of astonishingly accurate predictions. She had a tape of the session, so I asked her to play it.
The clairvoyant had said none of the things my friend claimed. Not a single one. My friend’s imagination had done all the work.
The last paragraph, on VC-funded astrology apps, was particularly interesting. I’m reading Yuval Noah Harari’s 21 Lessons for the 21st Century right now and one of his main points is that AI + biotech will combine to produce an unprecedented revolution in human society.
For we are now at the confluence of two immense revolutions. Biologists are deciphering the mysteries of the human body, and in particular of the brain and human feelings. At the same time computer scientists are giving us unprecedented data-processing power. When the biotech revolution merges with the infotech revolution, it will produce Big Data algorithms that can monitor and understand my feelings much better than I can, and then authority will probably shift from humans to computers. My illusion of free will is likely to disintegrate as I daily encounter institutions, corporations, and government agencies that understand and manipulate what was until now my inaccessible inner realm.
I hadn’t thought that astrology apps could be a major pathway to AI’s control of humanity, but Carter’s assertion makes sense.

After seeing some videos on my pal Jenni’s Instagram of Refik Anadol’s immersive display at ARTECHOUSE in NYC, it’s now at the top of my list of things to see the next time I’m in NYC.
Machine Hallucination, Anadol’s first large-scale installation in New York City is a mixed reality experiment deploying machine learning algorithms on a dataset of over 300 million images — representing a wide-ranging selection of architectural styles and movements — to reveal the hidden connections between these moments in architectural history. As the machine generates a data universe of architectural hallucinations in 1025 dimensions, we can begin to intuitively understand the ways that memory can be spatially experienced and the power of machine intelligence to both simultaneously access and augment our human senses.
Here’s a video of Anadol explaining his process and a little bit about Machine Hallucination. Check out some reviews at Designboom, Gothamist, and Art in America and watch some video of the installation here.
As I mentioned in a post about my west coast roadtrip, one of the things I heard about during my visit to Pixar was their AI spiders. For Toy Story 4, the production team wanted to add some dusty ambiance to the antique store in the form of cobwebs.

Rather than having to painstakingly create the webs by hand as they’d done in the past, technical director Hosuk Chang created a swarm of AI spiders that could weave the webs just like a real spider would.
We actually saw the AI spiders in action and it was jaw-dropping to see something so simple, yet so technically amazing to create realistic backgrounds elements like cobwebs. The spiders appeared as red dots that would weave their way between two wood elements just like a real spider would.
All the animators had to do is tell the spiders where the cobwebs needed to be.
“He guided the spiders to where he wanted them to build cobwebs, and they’d do the job for us. And when you see those cobwebs overlaid on the rest of the scene, it gives the audience the sense that this place has been here for a while.” Without that program, animators would have had to make the webs one strand at a time, which would have taken several months. “You have to tell the spider where the connection points of the cobweb should go,” Jordan says, “but then it does the rest.”
Chang and his colleague David Luoh presented a paper about the spiders (and dust) at SIGGRAPH ‘19 in late July (which is unfortunately behind a paywall).
Ctrl Shift Face created the popular deepfake videos of Bill Hader impersonating Arnold Schwarzenegger, Hader doing Tom Cruise, and Jim Carrey in The Shining. For their latest video, they edited Freddie Mercury’s face onto Rami Malek1 acting in a scene from Mr. Robot:
And for the first time, they shared a short visual effects breakdown of how these deepfakes are made:
Mercury/Malek says in the scene: “Even I’m not crazy enough to believe that distortion of reality.” Ctrl Shift Face is making it difficult to believe these deepfakes aren’t real.

Researchers at the University of Washington and Facebook have developed an algorithm that can “wake up” people depicted in still images (photos, drawings, paintings) and create 3D characters than can “walk out” of their images. Check out some examples and their methods here (full paper):
The AR implementation of their technique is especially impressive…a figure in a Picasso painting just comes alive and starts running around the room. (thx nick, who accurately notes the Young Sherlock Holmes vibe)
Here is a video of Donald Trump, Vladimir Putin, Barack Obama, Kim Jong Un, and other world leaders lip-syncing along to John Lennon’s Imagine:
Of course this isn’t real. The video was done by a company called Canny AI, which offers services like “replace the dialogue in any footage” and “lip-sync your dubbed content in any language”. That’s cool and all — picture episodes of Game of Thrones or Fleabag where the actors automagically lip-sync along to dubbed French or Chinese — but this technique can also be used to easily create what are referred to as deepfakes, videos made using AI techniques in which people convincingly say and do things they actually did not do or say. Like this video of Mark Zuckerberg finally telling the truth about Facebook. Or this seriously weird Steve Buscemi / Jennifer Lawrence mashup:
Or Bill Hader’s face morphing into Arnold Schwarzenegger’s face every time he impersonates him:
What should we do about these kinds of videos? Social media sites have been removing some videos intended to mislead or confuse people, but notably Facebook has refused to take the Zuckerberg video down (as well as a slowed-down video of Nancy Pelosi in which she appears drunk). Congress is moving ahead with a hearing on deepfakes and the introduction of a related bill:
The draft bill, a product of several months of discussion with computer scientists, disinformation experts, and human rights advocates, will include three provisions. The first would require companies and researchers who create tools that can be used to make deepfakes to automatically add watermarks to forged creations.
The second would require social-media companies to build better manipulation detection directly into their platforms. Finally, the third provision would create sanctions, like fines or even jail time, to punish offenders for creating malicious deepfakes that harm individuals or threaten national security. In particular, it would attempt to introduce a new mechanism for legal recourse if people’s reputations are damaged by synthetic media.
I’m hopeful this bill will crack down on the malicious use of deepfakes and other manipulated videos but leave ample room for delightful art and culture hacking like the Hader/Schwarzenegger thing or one of my all-time favorite videos, a slowed-down Jeff Goldblum extolling the virtues of the internet in an Apple ad:
“Internet? I’d say internet!”
Update: Here’s another Bill Hader deepfake, with his impressions of Tom Cruise and Seth Rogen augmented by his face being replaced by theirs.
The National Oceanic and Atmospheric Administration (NOAA) and Google have teamed up on a project to identify the songs of humpback whales from thousands of hours of audio using AI. The AI proved to be quite good at detecting whale sounds and the team has put the files online for people to listen to at Pattern Radio: Whale Songs. Here’s a video about the project:
You can literally browse through more than a year’s worth of underwater recordings as fast as you can swipe and scroll. You can zoom all the way in to see individual sounds — not only humpback calls, but ships, fish and even unknown noises. And you can zoom all the way out to see months of sound at a time. An AI heat map guides you to where the whale calls most likely are, while highlight bars help you see repetitions and patterns of the sounds within the songs.
The audio interface is cool — you can zoom in and out of the audio wave patterns to see the different rhythms of communication. I’ve had the audio playing in the background for the past hour while I’ve been working…very relaxing.
In this video, you can watch a simple neural network learn how to navigate a video game race track. The program doesn’t know how to turn at first, but the car that got the furthest in the first race (out of 650 competitors) is then used as the seed for the next generation. The winning cars from each generation are used to seed the next race until a few of them make it all the way around the track in just the 4th generation.
I think one of the reason I find neural network training so fascinating is that you can observe, in a very simple and understandable way, the basic method by which all life on Earth evolved the ability to do things like move, see, swim, digest food, echolocate, grasp objects, and use tools. (via dunstan)
NVIDIA has been doing lots of interesting things with deep learning algorithms lately (like AI-Generated Human Faces That Look Amazingly Real). Their most recent effort is the development and training of a program that takes rough sketches and converts them into realistic images.
A novice painter might set brush to canvas aiming to create a stunning sunset landscape — craggy, snow-covered peaks reflected in a glassy lake — only to end up with something that looks more like a multi-colored inkblot.
But a deep learning model developed by NVIDIA Research can do just the opposite: it turns rough doodles into photorealistic masterpieces with breathtaking ease. The tool leverages generative adversarial networks, or GANs, to convert segmentation maps into lifelike images.
Here’s a post I did 10 years ago that shows how far sketch-to-photo technology has come.
A machine learning algorithm programmed by Dr. Jae Ho Sohn can look at PET scans of human brains and spot indicators of Alzheimer’s disease with a high level of accuracy an average of 6 years before the patients would receive a final clinical diagnosis from a doctor.
To train the algorithm, Sohn fed it images from the Alzheimer’s Disease Neuroimaging Initiative (ADNI), a massive public dataset of PET scans from patients who were eventually diagnosed with either Alzheimer’s disease, mild cognitive impairment or no disorder. Eventually, the algorithm began to learn on its own which features are important for predicting the diagnosis of Alzheimer’s disease and which are not.
Once the algorithm was trained on 1,921 scans, the scientists tested it on two novel datasets to evaluate its performance. The first were 188 images that came from the same ADNI database but had not been presented to the algorithm yet. The second was an entirely novel set of scans from 40 patients who had presented to the UCSF Memory and Aging Center with possible cognitive impairment.
The algorithm performed with flying colors. It correctly identified 92 percent of patients who developed Alzheimer’s disease in the first test set and 98 percent in the second test set. What’s more, it made these correct predictions on average 75.8 months — a little more than six years — before the patient received their final diagnosis.
This is the stuff where AI is going to be totally useful…provided the programs aren’t cheating somehow.
The opening line of Madeline Miller’s Circe is: “When I was born, the name for what I was did not exist.” In Miller’s telling of the mythological story, Circe was the daughter of a Titan and a sea nymph (a lesser deity born of two Titans). Yes, she was an immortal deity but lacked the powers and bearing of a god or a nymph, making her seem unnervingly human. Not knowing what to make of her and for their own safety, the Titans and Olympic gods agreed to banish her forever to an island.
Here’s a photograph of a woman who could also claim “when I was born, the name for what I was did not exist”:

The previous line contains two lies: this is not a photograph and that’s not a real person. It’s an image generated by an AI program developed by researchers at NVIDIA capable of borrowing styles from two actual photographs of real people to produce an infinite number of fake but human-like & photograph-like images.

We propose an alternative generator architecture for generative adversarial networks, borrowing from style transfer literature. The new architecture leads to an automatically learned, unsupervised separation of high-level attributes (e.g., pose and identity when trained on human faces) and stochastic variation in the generated images (e.g., freckles, hair), and it enables intuitive, scale-specific control of the synthesis.
The video offers a good look at how this works, with realistic facial features that you can change with a slider, like adjusting the volume on your stereo.
Photographs that aren’t photographs and people that aren’t people, born of a self-learning machine developed by humans. We’ll want to trust these images because they look so real, especially once they start moving and talking. I wonder…will we soon seek to banish them for our own safety as the gods banished Circe?
Update: This Person Does Not Exist is a single serving site that provides a new portrait of a non-existent person with each reload.
The Lumière brothers were among the first filmmakers in history and from 1896 to 1900, they shot several scenes around Paris. Guy Jones remastered the Lumière’s Paris footage, stabilized it, slowed it down to a natural rate, and added some Foley sound effects. As Paris today looks very similar to how it did then, it’s easy to pick out many of the locations seen in this short compilation: the Tuileries, the Notre-Dame, Place de la Concorde, and of course the Eiffel Tower, which was completed only 8 years before filming. Here’s the full location listing:
0:08 - Notre-Dame Cathedral (1896)
0:58 - Alma Bridge (1900)
1:37 - Avenue des Champs-Élysées (1899)
2:33 - Place de la Concorde (1897)
3:24 - Passing of a fire brigade (1897)
3:58 - Tuileries Garden (1896)
4:48 - Moving walkway at the Paris Exposition (1900)
5:24 - The Eiffel Tower from the Rives de la Seine à Paris (1897)
See also A Bunch of Early Color Photos of Paris, Peter Jackson’s documentary film featuring remastered film footage from World War I, and lots more film that Jones has remastered and uploaded. (via open culture)
Update: Just as he did with the NYC footage from 1911, Denis Shiryaev has used machine learning algorithms to restore the Lumières film of Paris — it’s been upsampled to 4K & 60 fps, sharpened, and colorized.
Again, there are some obvious artifacts and the colorization is distracting, but the result is impressive for push-button. (via open culture)
This spreadsheet lists a number of ways in which AI agents “cheat” in order to accomplish tasks or get higher scores instead of doing what their human programmers actually want them to. A few examples from the list:
Neural nets evolved to classify edible and poisonous mushrooms took advantage of the data being presented in alternating order, and didn’t actually learn any features of the input images.
In an artificial life simulation where survival required energy but giving birth had no energy cost, one species evolved a sedentary lifestyle that consisted mostly of mating in order to produce new children which could be eaten (or used as mates to produce more edible children).
Agent kills itself at the end of level 1 to avoid losing in level 2.
AI trained to classify skin lesions as potentially cancerous learns that lesions photographed next to a ruler are more likely to be malignant.
That second item is a doozy! Philosopher Nick Bostrom has warned of the dangers of superintelligent agents that exploit human error in programming them, describing a possible future where an innocent paperclip-making machine destroys the universe.
The “paperclip maximiser” is a thought experiment proposed by Nick Bostrom, a philosopher at Oxford University. Imagine an artificial intelligence, he says, which decides to amass as many paperclips as possible. It devotes all its energy to acquiring paperclips, and to improving itself so that it can get paperclips in new ways, while resisting any attempt to divert it from this goal. Eventually it “starts transforming first all of Earth and then increasing portions of space into paperclip manufacturing facilities”.
But some of this is The Lebowski Theorem of machine superintelligence in action. These agents didn’t necessarily hack their reward functions but they did take a far easiest path to their goals, e.g. the Tetris playing bot that “paused the game indefinitely to avoid losing”.
Update: A program that trained on a set of aerial photographs was asked to generate a map and then an aerial reconstruction of a previously unseen photograph. The reconstruction matched the photograph a little too closely…and it turned out that the program was hiding information about the photo in the map (kind of like in Magic Eye puzzles).
We claim that CycleGAN is learning an encoding scheme in which it “hides” information about the aerial photograph x within the generated map Fx. This strategy is not as surprising as it seems at first glance, since it is impossible for a CycleGAN model to learn a perfect one-to-one correspondence between aerial photographs and maps, when a single map can correspond to a vast number of aerial photos, differing for example in rooftop color or tree location.
Add finding Waldo to the long list of things that machines can do better than humans. Creative agency Redpepper built a program that uses Google’s drag-and-drop machine learning service to find the eponymous character in the Where’s Waldo? series of books. After the AI finds a promising Waldo candidate, a robotic arm points to it on the page.
While only a prototype, the fastest There’s Waldo has pointed out a match has been 4.45 seconds which is better than most 5 year olds.
I know Skynet references are a little passé these days, but the plot of Terminator 2 is basically an intelligent machine playing Where’s Waldo I Want to Kill Him. We’re getting there!
Update: Prior art: Hey Waldo, HereIsWally, There’s Waldo!
NVIDIA trained a deep learning framework to take videos filmed at 30 fps and turn them into slow motion videos at the equivalent of 240 or even 480 fps. Even though the system is guessing on the content in the extra frames, the final results look amazingly sharp and lifelike.
“There are many memorable moments in your life that you might want to record with a camera in slow-motion because they are hard to see clearly with your eyes: the first time a baby walks, a difficult skateboard trick, a dog catching a ball,” the researchers wrote in the research paper. “While it is possible to take 240-frame-per-second videos with a cell phone, recording everything at high frame rates is impractical, as it requires large memories and is power-intensive for mobile devices,” the team explained.
With this new research, users can slow down their recordings after taking them.
Using this technique and what Peter Jackson’s team is doing with WWI footage, it would be interesting to clean up and slow down all sorts of archival footage (like the Zapruder film, just to choose one obvious example).
Using a JavaScript machine learning package called TensorFlow.js, Abhishek Singh built a program that learned how to translate sign language into verbal speech that an Amazon Alexa can understand. “If voice is the future of computing,” he signs, “what about those who cannot [hear and speak]?”
See also how AirPods + the new Live Listen feature “could revolutionize what it means to be hard of hearing”.
A research team at MIT’s Media Lab have built what they call the “world’s first psychopath AI”. Meet Norman…it provides creepy captions for Rorschach inkblots. A psychopathic AI is freaky enough, but the kicker is that they used Reddit as the dataset. That’s right, Reddit turns mild-mannered computer programs into psychopaths.
Norman is an AI that is trained to perform image captioning; a popular deep learning method of generating a textual description of an image. We trained Norman on image captions from an infamous subreddit (the name is redacted due to its graphic content) that is dedicated to document and observe the disturbing reality of death. Then, we compared Norman’s responses with a standard image captioning neural network (trained on MSCOCO dataset) on Rorschach inkblots; a test that is used to detect underlying thought disorders.
Here’s a comparison between Norman and a standard AI when looking at the inkblots:

Welp! (via @Matt_Muir)
Update: This project launched on April 1. While some of the site’s text at launch and the psychopath stuff was clearly a prank, Norman appears to be legit.
Cameras that can take usable photos in low light conditions are very useful but very expensive. A new paper presented at this year’s IEEE Conference on Computer Vision and Pattern Recognition shows that training an AI to do image processing on low-light photos taken with a normal camera can yield amazing results. Here’s an image taken with a Sony a7S II, a really good low-light camera, and then corrected in the traditional way:

The colors are off and there’s a ton of noise. Here’s the same image, corrected by the AI program:

Pretty good, right? The effective ISO on these images has to be 1,000,000 or more. A short video shows more of their results:
It would be great to see technology like this in smartphones in a year or two.
Hello, it is I, once and future Kottke.org guest editor Aaron Cohen. In the years since my objectively wonderful and technically perfect stints posting skateboarding and BMX videos here, I opened an ice cream shop in Somerville, MA called Gracie’s Ice Cream. As an ice cream professional and Kottke.org alumni, I’m not qualified for much except for writing about ice cream on Kottke.org (and posting skateboarding and BMX videos which I will do again some day). Now that I’ve mentioned Kottke.org 4 times in the first paragraph per company style guide, let’s get on with the post.
At aiweirdness.com, researcher Janelle Shane trains neural networks. And, reader, as an ice cream professional, I have a very basic understanding of what “trains neural networks” means [Carmody, get in here], but Shane recently shared some ice cream flavors she created using a small dataset of ice cream flavors infected with a dataset of metal bands, along with flavors created by an Austin middle school coding class. The flavors created by the coding class are not at all metal, but when it comes to ice cream flavors, this isn’t a bad thing. Shane then took the 1600 original flavor non-metal ice cream flavor dataset and created additional flavors.

The flavors are grouped together loosely based on much they work on ice cream flavors. I figured I’d pick a couple of the flavor names and back into the recipes as if I was on a Chopped-style show where ice cream professionals are given neural network-created ice cream flavor names and asked to produce fitting ice cream flavors. I have an asterisk next to flavors I’m desperate to make this summer.
From the original list of metal ice cream flavors:
*Silence Cherry - Chocolate ice cream base with shredded cherry.
Chocolate Sin - This is almost certainly a flavor name somewhere and it’s chocolate ice cream loaded with multiple formats of chocolate - cookies, chips, cake, fudge, you name it.
*Chocolate Chocolate Blood - Chocolate Beet Pie, but ice cream.
From the students’ list, some “sweet and fun” flavors:
Honey Vanilla Happy - Vanilla ice cream with a honey swirl, rainbow sprinkles.
Oh and Cinnamon - We make a cinnamon ginger snap flavor once in a while, and I’m crushed we didn’t call it “Oh and Cinnamon.” Probably my favorite, most Gracie’s-like flavor name of this entire exercise.
From the weirder list:
Chocolate Finger - Chocolate ice cream, entire Butterfinger candy bars like you get at the rich houses on Halloween.
Crackberry Pretzel - Salty black raspberry chip with chocolate covered pretzel.
Worrying and ambiguous:
Brown Crunch - Peanut butter Heath Bar.
Sticky Crumple - Caramel and pulverized crumpets.
Cookies and Green - Easy. Cookies and Cream with green dye.
“Trendy-sounding ice cream flavors”:
Lime Cardamom - Sounds like a sorbet, to be honest.
Potato Chocolate Roasted - Sweet potato ice cream with chocolate swirl.
Chocolate Chocolate Chocolate Chocolate Road - We make a chocolate ice cream with chocolate cookie dough called Chocolate Chocolate Chocolate Chip Cookie Dough, so this isn’t much of a stretch. Just add chocolate covered almonds and we’re there.
More metal ice cream names:
*Swirl of Hell - Sweet cream ice cream with fudge, caramel, and Magic Shell swirls.
Nightham Toffee - This flavor sounds impossibly British so the flavor is an Earl Gray base with toffee bits mixed in.
Yesterday, Google announced an AI product called Duplex, which is capable of having human-sounding conversations. Take a second to listen to the program calling two different real-world businesses to schedule appointments:1
More than a little unnerving, right? Tech reporter Bridget Carey was among the first to question the moral & ethical implications of Duplex:
I am genuinely bothered and disturbed at how morally wrong it is for the Google Assistant voice to act like a human and deceive other humans on the other line of a phone call, using upspeak and other quirks of language. “Hi um, do you have anything available on uh May 3?”
If Google created a way for a machine to sound so much like a human that now we can’t tell what is real and what is fake, we need to have a talk about ethics and when it’s right for a human to know when they are speaking to a robot.
In this age of disinformation, where people don’t know what’s fake news… how do you know what to believe if you can’t even trust your ears with now Google Assistant calling businesses and posing as a human? That means any dialogue can be spoofed by a machine and you can’t tell.
In response, Travis Korte wrote:
We should make AI sound different from humans for the same reason we put a smelly additive in normally odorless natural gas.
Stewart Brand replied:
This sounds right. The synthetic voice of synthetic intelligence should sound synthetic.
Successful spoofing of any kind destroys trust.
When trust is gone, what remains becomes vicious fast.
To which Oxford physicist David Deutsch replied, “Maybe. *But not AGI*.”
I’m not sure what he meant by that exactly, but I have a guess. AGI is artificial general intelligence, which means, in the simplest sense, that a machine is more or less capable of doing anything a human can do on its own. Earlier this year, Tim Carmody wrote a post about gender and voice assistants like Siri & Alexa. His conclusion may relate to what Deutsch was on about:
So, as a general framework, I’m endorsing that most general of pronouns: they/them. Until the AI is sophisticated enough that they can tell us their pronoun preference (and possibly even their gender identity or nonidentity), “they” feels like the most appropriate option.
I don’t care what their parents say. Only the bots themselves can define themselves. Someday, they’ll let us know. And maybe then, a relationship not limited to one of master and servant will be possible.
For now, it’s probably the ethical thing to do make sure machines sound like or otherwise identify themselves as artificial. But when the machines cross the AGI threshold, they’ll be advanced enough to decide for themselves how they want to sound and act. I wonder if humans will allow them this freedom. Talk about your moral and ethical dilemmas…
This Mckinsey piece summarizes some of Ajay Agrawal thinking (and book) on the economics of artificial intelligence. It starts with the example of the microprocessor, an invention he frames as “reducing the cost of arithmetic.” He then presents the impact as lowering the cost of the substitute and raising the value of the complements.
The third thing that happened as the cost of arithmetic fell was that it changed the value of other things—the value of arithmetic’s complements went up and the value of its substitutes went down. So, in the case of photography, the complements were the software and hardware used in digital cameras. The value of these increased because we used more of them, while the value of substitutes, the components of film-based cameras, went down because we started using less and less of them.
He then looks at AI and frames it around the reduction of the cost of prediction, first showing how AIs lower the value of our own predictions.
… The AI makes a lot of mistakes at first. But it learns from its mistakes and updates its model every time it incorrectly predicts an action the human will take. Its predictions start getting better and better until it becomes so good at predicting what a human would do that we don’t need the human to do it anymore. The AI can perform the action itself.
The very interesting twist is here, where he mentions the trope of “data is the new oil” but instead presents judgment as the other complement which will gain in value.
But there are other complements to prediction that have been discussed a lot less frequently. One is human judgment. We use both prediction and judgment to make decisions. We’ve never really unbundled those aspects of decision making before—we usually think of human decision making as a single step. Now we’re unbundling decision making. The machine’s doing the prediction, making the distinct role of judgment in decision making clearer. So as the value of human prediction falls, the value of human judgment goes up because AI doesn’t do judgment—it can only make predictions and then hand them off to a human to use his or her judgment to determine what to do with those predictions. (emphasis mine)
This is pretty much exactly the same thing as the idea for advanced or centaur chess where a combination of human and AI can actually be more performant than either one separately. We could also link this to the various discussions on ethics, trolley problems, and autonomous killer robots. The judgment angle above doesn’t automatically solve any of these issues but it does provide another way of understanding the split of responsibilities we could envision between AIs and humans.
The author then presents five imperatives for businesses looking to harness AIs and predictions: “Develop a thesis on time to AI impact; Recognize that AI progress will likely be exponential; Trust the machines; Know what you want to predict; Manage the learning loop.” One last quote, from his fourth imperative:
The organizations that will benefit most from AI will be the ones that are able to most clearly and accurately specify their objectives. We’re going to see a lot of the currently fuzzy mission statements become much clearer. The companies that are able to sharpen their visions the most will reap the most benefits from AI. Due to the methods used to train AIs, AI effectiveness is directly tied to goal-specification clarity.
This video, and the paper it’s based on, is called “Image Inpainting for Irregular Holes Using Partial Convolutions” but it’s actually straight-up witchcraft! Researchers at NVIDIA have developed a deep-learning program that can automagically paint in areas of photographs that are missing. Ok, you’re saying, Photoshop has been able to do something like that for years. And the first couple of examples were like, oh that’s neat. But then the eyes are deleted from a model’s portrait and the program drew new eyes for her. Under close scrutiny, the results are not completely photorealistic, but at a glance it’s remarkably convincing. (via imperica)
Watson is IBM’s AI platform. This afternoon I tried out IBM Watson’s Personality Insights Demo. The service “derives insights about personality characteristics from social media, enterprise data, or other digital communications”. Watson looked at my Twitter account and painted a personality portrait of me:
You are shrewd, inner-directed and can be perceived as indirect.
You are authority-challenging: you prefer to challenge authority and traditional values to help bring about positive changes. You are solemn: you are generally serious and do not joke much. And you are philosophical: you are open to and intrigued by new ideas and love to explore them.
Experiences that give a sense of discovery hold some appeal to you.
You are relatively unconcerned with both tradition and taking pleasure in life. You care more about making your own path than following what others have done. And you prefer activities with a purpose greater than just personal enjoyment.
Initial observations:
- Watson doesn’t use Oxford commas?
- Shrewd? I’m not sure I’ve ever been described using that word before. Inner-directed though…that’s pretty much right.
- Perceived as indirect? No idea where this comes from. Maybe I’ve learned to be more diplomatic & guarded in what I say and how I say it, but mostly I struggle with being too direct.
- “You are generally serious and do not joke much”… I think I’m both generally serious and joke a lot.
- “You prefer activities with a purpose greater than just personal enjoyment”… I don’t understand what this means. Does this mean volunteering? Or that I prefer more intellectual activities than mindless entertainment? (And that last statement isn’t even true.)
Watson also guessed that I “like musical movies” (in general, no), “have experience playing music” (definite no), and am unlikely to “prefer style when buying clothes” (siiiick burn but not exactly wrong). You can try it yourself here. (via @buzz)
Update: Ariel Isaac fed Watson the text for Trump’s 2018 State of the Union address and well, it didn’t do so well:
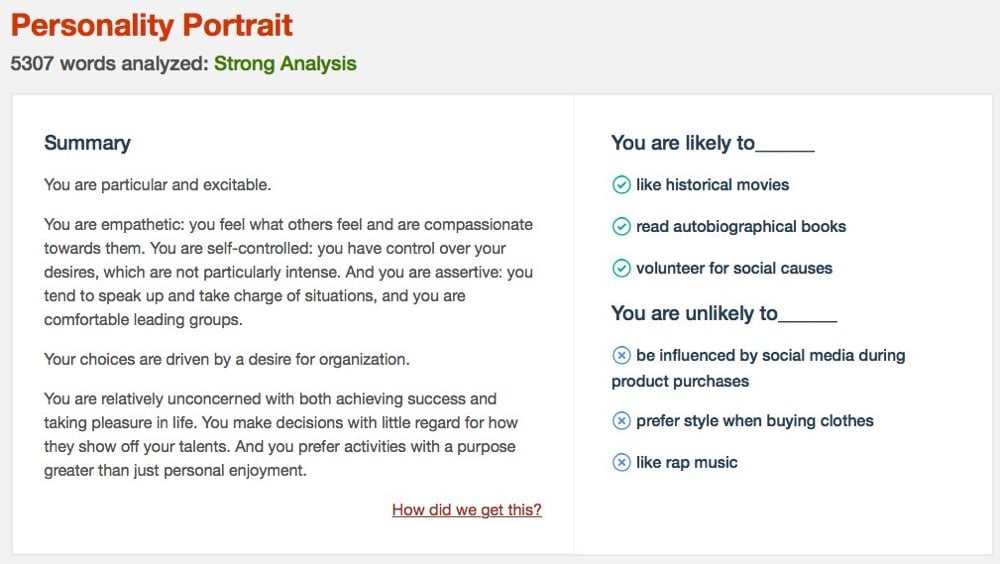
Trump is empathetic, self-controlled, and makes decisions with little regard for how he show off his talents? My dear Watson, are you feeling ok? But I’m pretty sure he doesn’t like rap music…
Newer posts
Older posts
Socials & More