The distribution of letters in English words
David Taylor analyzed a corpus of English words to see where each letter of the alphabet fell and graphed the results.
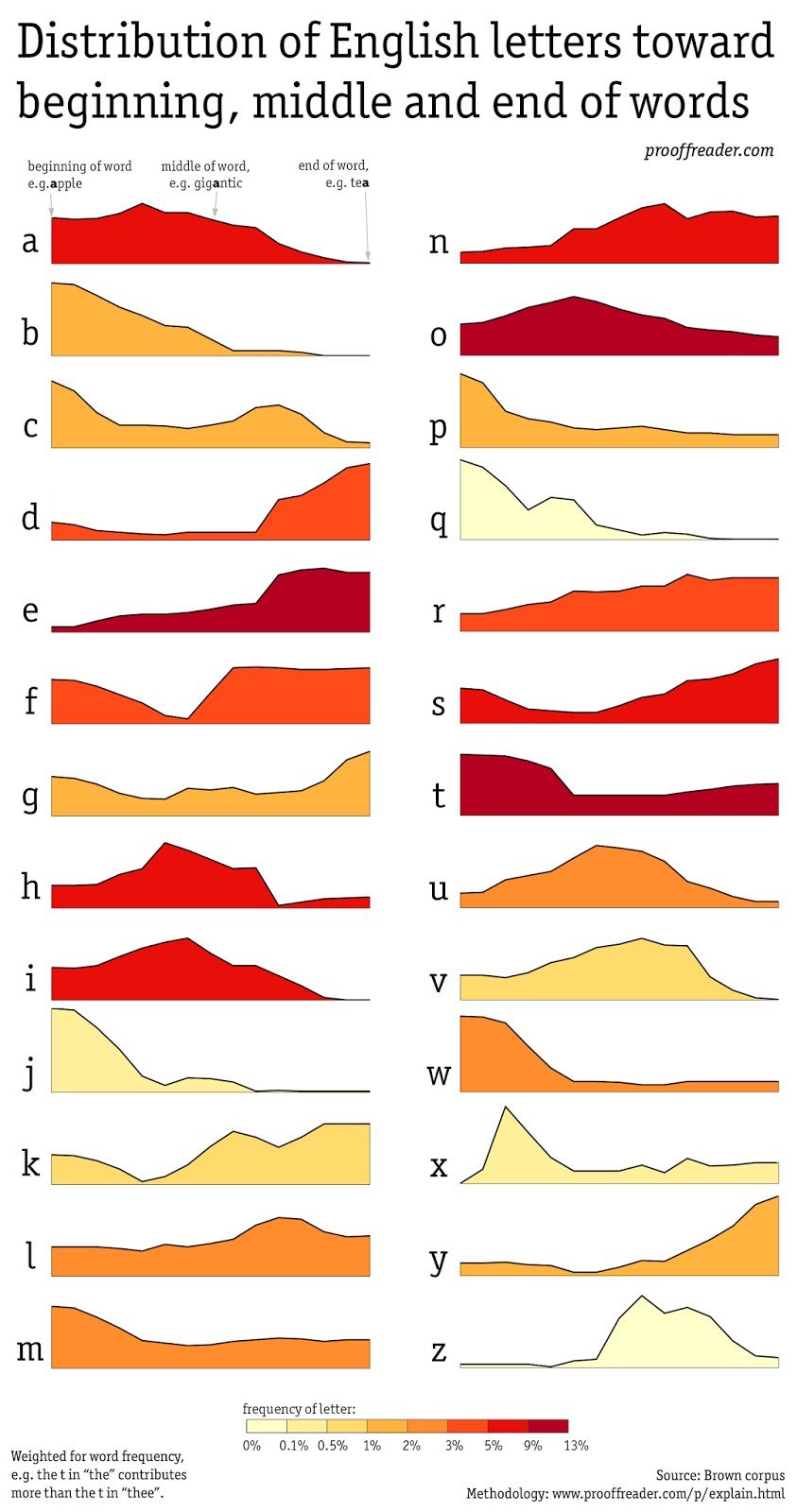
No surprise that “q” and “j” are found mostly at the beginnings of words and “y” and “d” at the ends. More interesting are the few letters with more even distribution throughout words, like “l”, “r”, and even “o”. Note that this analysis is based on a corpus of words in use, not on a dictionary:
I used a corpus rather than a dictionary so that the visualization would be weighted towards true usage. In other words, the most common word in English, “the” influences the graphs far more than, for example, “theocratic”.
Taylor explained his methodology in a second geekier post. (via @tedgioia)

Socials & More